mirror of
https://github.com/speed47/spectre-meltdown-checker.git
synced 2026-06-18 04:23:11 +02:00
Compare commits
6 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
7f5256f15e | ||
|
|
7a3224ad61 | ||
|
|
31cf549c75 | ||
|
|
b305cc48c3 | ||
|
|
12f545dc45 | ||
|
|
94356c4992 |
@@ -1,36 +0,0 @@
|
||||
name: autoupdate
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
schedule:
|
||||
- cron: '42 9 * * *'
|
||||
|
||||
permissions:
|
||||
pull-requests: write
|
||||
|
||||
jobs:
|
||||
autoupdate:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
- name: Install prerequisites
|
||||
run: sudo apt-get update && sudo apt-get install -y --no-install-recommends iucode-tool sqlite3 unzip
|
||||
- name: Update microcode versions
|
||||
run: ./spectre-meltdown-checker.sh --update-builtin-fwdb
|
||||
- name: Check git diff
|
||||
id: diff
|
||||
run: |
|
||||
echo change="$(git diff spectre-meltdown-checker.sh | awk '/MCEDB/ { if(V) { print V" to "$4; exit } else { V=$4 } }')" >> "$GITHUB_OUTPUT"
|
||||
echo nbdiff="$(git diff spectre-meltdown-checker.sh | grep -cE -- '^\+# [AI],')" >> "$GITHUB_OUTPUT"
|
||||
git diff
|
||||
cat "$GITHUB_OUTPUT"
|
||||
- name: Create Pull Request if needed
|
||||
if: steps.diff.outputs.nbdiff != '0'
|
||||
uses: peter-evans/create-pull-request@v7
|
||||
with:
|
||||
branch: autoupdate-fwdb
|
||||
commit-message: "update: fwdb from ${{ steps.diff.outputs.change }}, ${{ steps.diff.outputs.nbdiff }} microcode changes"
|
||||
title: "[Auto] Update fwdb from ${{ steps.diff.outputs.change }}"
|
||||
body: |
|
||||
Automated PR to update fwdb from ${{ steps.diff.outputs.change }}
|
||||
Detected ${{ steps.diff.outputs.nbdiff }} microcode changes
|
||||
@@ -1,111 +0,0 @@
|
||||
name: build
|
||||
|
||||
on:
|
||||
push:
|
||||
branches:
|
||||
- test
|
||||
- source
|
||||
|
||||
jobs:
|
||||
build:
|
||||
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v6
|
||||
with:
|
||||
persist-credentials: true
|
||||
- name: install prerequisites
|
||||
run: sudo apt-get update && sudo apt-get install -y shellcheck shfmt jq sqlite3 iucode-tool make
|
||||
- name: build and check
|
||||
run: |
|
||||
make build fmt-check shellcheck
|
||||
mv spectre-meltdown-checker.sh dist/
|
||||
- name: check direct execution
|
||||
run: |
|
||||
expected=$(cat .github/workflows/expected_cve_count)
|
||||
cd dist
|
||||
nb=$(sudo ./spectre-meltdown-checker.sh --batch json | jq '.[]|.CVE' | wc -l)
|
||||
if [ "$nb" -ne "$expected" ]; then
|
||||
echo "Invalid number of CVEs reported: $nb instead of $expected"
|
||||
exit 1
|
||||
else
|
||||
echo "OK $nb CVEs reported"
|
||||
fi
|
||||
- name: check docker compose run execution
|
||||
run: |
|
||||
expected=$(cat .github/workflows/expected_cve_count)
|
||||
cd dist
|
||||
docker compose build
|
||||
nb=$(docker compose run --rm spectre-meltdown-checker --batch json | jq '.[]|.CVE' | wc -l)
|
||||
if [ "$nb" -ne "$expected" ]; then
|
||||
echo "Invalid number of CVEs reported: $nb instead of $expected"
|
||||
exit 1
|
||||
else
|
||||
echo "OK $nb CVEs reported"
|
||||
fi
|
||||
- name: check docker run execution
|
||||
run: |
|
||||
expected=$(cat .github/workflows/expected_cve_count)
|
||||
cd dist
|
||||
docker build -t spectre-meltdown-checker .
|
||||
nb=$(docker run --rm --privileged -v /boot:/boot:ro -v /dev/cpu:/dev/cpu:ro -v /lib/modules:/lib/modules:ro spectre-meltdown-checker --batch json | jq '.[]|.CVE' | wc -l)
|
||||
if [ "$nb" -ne "$expected" ]; then
|
||||
echo "Invalid number of CVEs reported: $nb instead of $expected"
|
||||
exit 1
|
||||
else
|
||||
echo "OK $nb CVEs reported"
|
||||
fi
|
||||
- name: check fwdb update (separated)
|
||||
run: |
|
||||
cd dist
|
||||
nbtmp1=$(find /tmp 2>/dev/null | wc -l)
|
||||
./spectre-meltdown-checker.sh --update-fwdb; ret=$?
|
||||
if [ "$ret" != 0 ]; then
|
||||
echo "Non-zero return value: $ret"
|
||||
exit 1
|
||||
fi
|
||||
nbtmp2=$(find /tmp 2>/dev/null | wc -l)
|
||||
if [ "$nbtmp1" != "$nbtmp2" ]; then
|
||||
echo "Left temporary files!"
|
||||
exit 1
|
||||
fi
|
||||
if ! [ -e ~/.mcedb ]; then
|
||||
echo "No .mcedb file found after updating fwdb"
|
||||
exit 1
|
||||
fi
|
||||
- name: check fwdb update (builtin)
|
||||
run: |
|
||||
cd dist
|
||||
nbtmp1=$(find /tmp 2>/dev/null | wc -l)
|
||||
./spectre-meltdown-checker.sh --update-builtin-fwdb; ret=$?
|
||||
if [ "$ret" != 0 ]; then
|
||||
echo "Non-zero return value: $ret"
|
||||
exit 1
|
||||
fi
|
||||
nbtmp2=$(find /tmp 2>/dev/null | wc -l)
|
||||
if [ "$nbtmp1" != "$nbtmp2" ]; then
|
||||
echo "Left temporary files!"
|
||||
exit 1
|
||||
fi
|
||||
- name: create a pull request to ${{ github.ref_name }}-build
|
||||
run: |
|
||||
tmpdir=$(mktemp -d)
|
||||
mv ./dist/* .github $tmpdir/
|
||||
rm -rf ./dist
|
||||
git fetch origin ${{ github.ref_name }}-build
|
||||
git checkout -f ${{ github.ref_name }}-build
|
||||
mv $tmpdir/* .
|
||||
mkdir -p .github
|
||||
rsync -vaP --delete $tmpdir/.github/ .github/
|
||||
git add --all
|
||||
echo =#=#= DIFF CACHED
|
||||
git diff --cached
|
||||
echo =#=#= STATUS
|
||||
git status
|
||||
echo =#=#= COMMIT
|
||||
git config --global user.name "github-actions[bot]"
|
||||
git config --global user.email "41898282+github-actions[bot]@users.noreply.github.com"
|
||||
git log ${{ github.ref }} -1 --format=format:'%s%n%n built from commit %H%n dated %ai%n by %an (%ae)%n%n %b'
|
||||
git log ${{ github.ref }} -1 --format=format:'%s%n%n built from commit %H%n dated %ai%n by %an (%ae)%n%n %b' | git commit -F -
|
||||
git push
|
||||
@@ -1 +0,0 @@
|
||||
21
|
||||
@@ -1,33 +0,0 @@
|
||||
name: 'Manage stale issues and PRs'
|
||||
|
||||
on:
|
||||
schedule:
|
||||
- cron: '37 7 * * *'
|
||||
workflow_dispatch:
|
||||
inputs:
|
||||
action:
|
||||
description: "dry-run"
|
||||
required: true
|
||||
default: "dryrun"
|
||||
type: choice
|
||||
options:
|
||||
- dryrun
|
||||
- apply
|
||||
|
||||
permissions:
|
||||
issues: write
|
||||
pull-requests: write
|
||||
|
||||
jobs:
|
||||
stale:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/stale@v10
|
||||
with:
|
||||
any-of-labels: 'needs-more-info,answered'
|
||||
labels-to-remove-when-unstale: 'needs-more-info,answered'
|
||||
days-before-stale: 30
|
||||
days-before-close: 7
|
||||
stale-issue-label: stale
|
||||
remove-stale-when-updated: true
|
||||
debug-only: ${{ case(inputs.action == 'apply', false, true) }}
|
||||
@@ -0,0 +1,4 @@
|
||||
__pycache__/
|
||||
*.py[cod]
|
||||
*.egg-info/
|
||||
.venv/
|
||||
@@ -1,7 +0,0 @@
|
||||
FROM alpine:latest
|
||||
|
||||
RUN apk --update --no-cache add kmod binutils grep perl zstd wget sharutils unzip sqlite procps coreutils iucode-tool gzip xz bzip2 lz4
|
||||
|
||||
COPY spectre-meltdown-checker.sh /
|
||||
|
||||
ENTRYPOINT ["/spectre-meltdown-checker.sh"]
|
||||
@@ -1,145 +0,0 @@
|
||||
# Questions
|
||||
|
||||
- [What to expect from this tool?](#what-to-expect-from-this-tool)
|
||||
- [Why was this script written in the first place?](#why-was-this-script-written-in-the-first-place)
|
||||
- [Why are those vulnerabilities so different than regular CVEs?](#why-are-those-vulnerabilities-so-different-than-regular-cves)
|
||||
- [What do "affected", "vulnerable" and "mitigated" mean exactly?](#what-do-affected-vulnerable-and-mitigated-mean-exactly)
|
||||
- [What are the main design decisions regarding this script?](#what-are-the-main-design-decisions-regarding-this-script)
|
||||
- [Everything is indicated in `sysfs` now, is this script still useful?](#everything-is-indicated-in-sysfs-now-is-this-script-still-useful)
|
||||
- [How does this script work?](#how-does-this-script-work)
|
||||
- [Which BSD OSes are supported?](#which-bsd-oses-are-supported)
|
||||
- [Why is my OS not supported?](#why-is-my-os-not-supported)
|
||||
- [The tool says there is an updated microcode for my CPU, but I don't have it!](#the-tool-says-there-is-an-updated-microcode-for-my-cpu-but-i-dont-have-it)
|
||||
- [The tool says that I need a more up-to-date microcode, but I have the more recent version!](#the-tool-says-that-i-need-a-more-up-to-date-microcode-but-i-have-the-more-recent-version)
|
||||
- [Which rules are governing the support of a CVE in this tool?](#which-rules-are-governing-the-support-of-a-cve-in-this-tool)
|
||||
|
||||
# Answers
|
||||
|
||||
## What to expect from this tool?
|
||||
|
||||
This tool does its best to determine where your system stands on each of the collectively named [transient execution](https://en.wikipedia.org/wiki/Transient_execution_CPU_vulnerability) vulnerabilities (also sometimes called "speculative execution" vulnerabilities) that were made public since early 2018. It doesn't attempt to run any kind of exploit, and can't guarantee that your system is secure, but rather helps you verifying if your system is affected, and if it is, checks whether it has the known mitigations in place to avoid being vulnerable.
|
||||
Some mitigations could also exist in your kernel that this script doesn't know (yet) how to detect, or it might falsely detect mitigations that in the end don't work as expected (for example, on backported or modified kernels).
|
||||
|
||||
Please also note that for Spectre vulnerabilities, all software can possibly be exploited, this tool only verifies that the kernel (which is the core of the system) you're using has the proper protections in place. Verifying all the other software is out of the scope of this tool. As a general measure, ensure you always have the most up to date stable versions of all the software you use, especially for those who are exposed to the world, such as network daemons and browsers.
|
||||
|
||||
This tool has been released in the hope that it'll be useful, but don't use it to jump to definitive conclusions about your security: hardware vulnerabilities are [complex beasts](#why-are-those-vulnerabilities-so-different-than-regular-cves), and collective understanding of each vulnerability is evolving with time.
|
||||
|
||||
## Why was this script written in the first place?
|
||||
|
||||
The first commit of this script is dated *2018-01-07*, only 4 days after the world first heard about the Meltdown and the Spectre attacks. With those attacks disclosure, a _whole new range of vulnerabilities_ that were previously thought to be mostly theoretical and only possible in very controlled environments (labs) - hence of little interest for most except researchers - suddenly became completely mainstream and apparently trivial to conduct on an immensely large number of systems.
|
||||
|
||||
On the few hours and days after that date, the whole industry went crazy. Proper, verified information about these vulnerabilities was incredibly hard to find, because before this, even the CPU vendors never had to deal with managing security vulnerabilities at scale, as software vendors do since decades. There were a lot of FUD, and the apparent silence of the vendors was enough for most to fear the worst. The whole industry had everything to learn about this new type of vulnerabilities. However, most systems administrators had a few simple questions:
|
||||
|
||||
- Am **I** vulnerable? And if yes,
|
||||
- What do I have to do to mitigate these vulnerabilities on **my** system?
|
||||
|
||||
Unfortunately, answering those questions was very difficult (and still is to some extent), even if the safe answer to the first question was "you probably are". This script was written to try to give simple answers to those simple questions, and was made to evolve as the information about these vulnerabilities became available. On the first few days, there was several new versions published **per day**.
|
||||
|
||||
## Why are those vulnerabilities so different than regular CVEs?
|
||||
|
||||
Those are hardware vulnerabilities, while most of the CVEs we see everyday are software vulnerabilities. A quick comparison would be:
|
||||
|
||||
Software vulnerability:
|
||||
- Can be fixed? Yes.
|
||||
- How to fix? Update the software (or uninstall it!)
|
||||
|
||||
Hardware vulnerability:
|
||||
- Can be fixed? No, only mitigated (or buy new hardware!)
|
||||
- How to ~~fix~~ mitigate? In the worst case scenario, 5 "layers" need to be updated: the microcode/firmware, the host OS kernel, the hypervisor, the VM OS kernel, and possibly all the software running on the machine. Sometimes only a subset of those layers need to be updated. In yet other cases, there can be several possible mitigations for the same vulnerability, implying different layers. Yes, it can get horribly complicated.
|
||||
|
||||
A more detailed video explanation is available here: https://youtu.be/2gB9U1EcCss?t=425
|
||||
|
||||
## What do "affected", "vulnerable" and "mitigated" mean exactly?
|
||||
|
||||
- **Affected** means that your CPU's hardware, as it went out of the factory, is known to be concerned by a specific vulnerability, i.e. the vulnerability applies to your hardware model. Note that it says nothing about whether a given vulnerability can actually be used to exploit your system. However, an unaffected CPU will never be vulnerable, and doesn't need to have mitigations in place.
|
||||
- **Vulnerable** implies that you're using an **affected** CPU, and means that a given vulnerability can be exploited on your system, because no (or insufficient) mitigations are in place.
|
||||
- **Mitigated** implies that a previously **vulnerable** system has followed all the steps (updated all the required layers) to ensure a given vulnerability cannot be exploited. About what "layers" mean, see [the previous question](#why-are-those-vulnerabilities-so-different-than-regular-cves).
|
||||
|
||||
## What are the main design decisions regarding this script?
|
||||
|
||||
There are a few rules that govern how this tool is written.
|
||||
|
||||
1) It should be okay to run this script in a production environment. This implies, but is not limited to:
|
||||
|
||||
* 1a. Never modify the system it's running on, and if it needs to e.g. load a kernel module it requires, that wasn't loaded before it was launched, it'll take care to unload it on exit
|
||||
* 1b. Never attempt to "fix" or "mitigate" any vulnerability, or modify any configuration. It just reports what it thinks is the status of your system. It leaves all decisions to the sysadmin.
|
||||
* 1c. Never attempt to run any kind of exploit to tell whether a vulnerability is mitigated, because it would violate 1a), could lead to unpredictable system behavior, and might even lead to wrong conclusions, as some PoC must be compiled with specific options and prerequisites, otherwise giving wrong information (especially for Spectre). If you want to run PoCs, do it yourself, but please read carefully about the PoC and the vulnerability. PoCs about a hardware vulnerability are way more complicated and prone to false conclusions than PoCs for software vulnerabilities.
|
||||
|
||||
2) Never look at the kernel version to tell whether it supports mitigation for a given vulnerability. This implies never hardcoding version numbers in the script. This would defeat the purpose: this script should be able to detect mitigations in unknown kernels, with possibly backported or forward-ported patches. Also, don't believe what `sysfs` says, when possible. See the next question about this.
|
||||
|
||||
3) Never look at the microcode version to tell whether it has the proper mechanisms in place to support mitigation for a given vulnerability. This implies never hardcoding version numbers in the script. Instead, look for said mechanisms, as the kernel would do.
|
||||
|
||||
4) When a CPU is not known to be explicitly unaffected by a vulnerability, make the assumption that it is. This strong design choice has it roots in the early speculative execution vulnerability days (see [this answer](#why-was-this-script-written-in-the-first-place)), and is still a good approach as of today.
|
||||
|
||||
## Everything is indicated in `sysfs` now, is this script still useful?
|
||||
|
||||
A lot as changed since 2018. Nowadays, the industry adapted and this range of vulnerabilities is almost "business as usual", as software vulnerabilities are. However, due to their complexity, it's still not as easy as just checking a version number to ensure a vulnerability is closed.
|
||||
|
||||
Granted, we now have a standard way under Linux to check whether our system is affected, vulnerable, mitigated against most of these vulnerabilities. By having a look at the `sysfs` hierarchy, and more precisely the `/sys/devices/system/cpu/vulnerabilities/` folder, one can have a pretty good insight about its system state for each of the listed vulnerabilities. Note that the output can be a little different with some vendors (e.g. Red Hat has some slightly different output than the vanilla kernel for some vulnerabilities), but it's still a gigantic leap forward, given where we were in 2018 when this script was started, and it's very good news. The kernel is the proper place to have this because the kernel knows everything about itself (the mitigations it might have), and the CPU (its model, and microcode features that are exposed). Note however that some vulnerabilities are not reported through this file hierarchy at all, such as Zenbleed.
|
||||
|
||||
However I see a few reasons why this script might still be useful to you, and that's why its development has not halted when the `sysfs` hierarchy came out:
|
||||
|
||||
- A given version of the kernel doesn't have knowledge about the future. To put it in another way: a given version of the kernel only has the understanding of a vulnerability available at the time it was compiled. Let me explain this: when a new vulnerability comes out, new versions of the microcode and kernels are released, with mitigations in place. With such a kernel, a new `sysfs` entry will appear. However, after a few weeks or months, corner cases can be discovered, previously-thought unaffected CPUs can turn out to be affected in the end, and sometimes mitigations can end up being insufficient. Of course, if you're always running the latest kernel version from kernel.org, this issue might be limited for you. The spectre-meltdown-checker script doesn't depend on a kernel's knowledge and understanding of a vulnerability to compute its output. That is, unless you tell it to (using the `--sysfs-only` option).
|
||||
|
||||
- Mitigating a vulnerability completely can sometimes be tricky, and have a lot of complicated prerequisites, depending on your kernel version, CPU vendor, model and even sometimes stepping, CPU microcode, hypervisor support, etc. The script gives a very detailed insight about each of the prerequisites of mitigation for every vulnerability, step by step, hence pointing out what is missing on your system as a whole to completely mitigate an issue.
|
||||
|
||||
- The script can be pointed at a kernel image, and will deep dive into it, telling you if this kernel will mitigate vulnerabilities that might be present on your system. This is a good way to verify before booting a new kernel, that it'll mitigate the vulnerabilities you expect it to, especially if you modified a few config options around these topics.
|
||||
|
||||
- The script will also work regardless of the custom patches that might be integrated in the kernel you're running (or you're pointing it to, in offline mode), and completely ignores the advertised kernel version, to tell whether a given kernel mitigates vulnerabilities. This is especially useful for non-vanilla kernel, where patches might be backported, sometimes silently (this has already happened, too).
|
||||
|
||||
- Educational purposes: the script gives interesting insights about a vulnerability, and how the different parts of the system work together to mitigate it.
|
||||
|
||||
There are probably other reasons, but that are the main ones that come to mind. In the end, of course, only you can tell whether it's useful for your use case ;)
|
||||
|
||||
## How does this script work?
|
||||
|
||||
On one hand, the script gathers information about your CPU, and the features exposed by its microcode. To do this, it uses the low-level CPUID instruction (through the `cpuid` kernel module under Linux, and the `cpucontrol` tool under BSD), and queries to the MSR registers of your CPU (through the `msr` kernel module under Linux, and the `cpucontrol` tool under BSD).
|
||||
|
||||
On another hand, the script looks into the kernel image your system is running on, for clues about the mitigations it supports. Of course, this is very specific for each operating system, even if the implemented mitigation is functionally the same, the actual code is completely specific. As you can imagine, the Linux kernel code has a few in common with a BSD kernel code, for example. Under Linux, the script supports looking into the kernel image, and possibly the System.map and kernel config file, if these are available. Under BSD, it looks into the kernel file only.
|
||||
|
||||
Then, for each vulnerability it knows about, the script decides whether your system is [affected, vulnerable, and mitigated](#what-do-affected-vulnerable-and-mitigated-mean-exactly) against it, using the information it gathered about your hardware and your kernel.
|
||||
|
||||
## Which BSD OSes are supported?
|
||||
|
||||
For the BSD range of operating systems, the script will work as long as the BSD you're using supports `cpuctl` and `linprocfs`. This is not the case for OpenBSD for example. Known BSD flavors having proper support are: FreeBSD, NetBSD, DragonflyBSD. Derivatives of those should also work. To know why other BSDs will likely never be supported, see [why is my OS not supported?](#why-is-my-os-not-supported).
|
||||
|
||||
## Why is my OS not supported?
|
||||
|
||||
This tool only supports Linux, and [some flavors of BSD](#which-bsd-oses-are-supported). Other OSes will most likely never be supported, due to [how this script works](#how-does-this-script-work). It would require implementing these OSes specific way of querying the CPU. It would also require to get documentation (if available) about how this OS mitigates each vulnerability, down to this OS kernel code, and if documentation is not available, reverse-engineer the difference between a known old version of a kernel, and a kernel that mitigates a new vulnerability. This means that all the effort has to be duplicated times the number of supported OSes, as everything is specific, by construction. It also implies having a deep understanding of every OS, which takes years to develop. However, if/when other tools appear for other OSes, that share the same goal of this one, they might be listed here as a convenience.
|
||||
|
||||
## The tool says there is an updated microcode for my CPU, but I don't have it!
|
||||
|
||||
Even if your operating system is fully up to date, the tool might still tell you that there is a more recent microcode version for your CPU. Currently, it uses (and merges) information from 4 sources:
|
||||
|
||||
- The official [Intel microcode repository](https://github.com/intel/Intel-Linux-Processor-Microcode-Data-Files)
|
||||
- The awesome platomav's [MCExtractor database](https://github.com/platomav/MCExtractor) for non-Intel CPUs
|
||||
- The official [linux-firmware](https://git.kernel.org/pub/scm/linux/kernel/git/firmware/linux-firmware.git) repository for AMD
|
||||
- Specific Linux kernel commits that sometimes hardcode microcode versions, such as for [Zenbleed](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=522b1d69219d8f083173819fde04f994aa051a98) or for the bad [Spectre](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/arch/x86/kernel/cpu/intel.c#n141) microcodes
|
||||
|
||||
Generally, it means a more recent version of the microcode has been seen in the wild. However, fully public availability of this microcode might be limited yet, or your OS vendor might have chosen not to ship this new version (yet), maybe because it's currently being tested, or for other reasons. This tool can't tell you when or if this will be the case. You should ask your vendor about it. Technically, you can still go and upgrade your microcode yourself, and use this tool to confirm whether you did it successfully. Updating the microcode for you is out of the scope of this tool, as this would violate [rule 1b](#what-are-the-main-design-decisions-regarding-this-script).
|
||||
|
||||
## The tool says that I need a more up-to-date microcode, but I have the more recent version!
|
||||
|
||||
This can happen for a few reasons:
|
||||
|
||||
- Your CPU is no longer supported by the vendor. In that case, new versions of the microcode will never be published, and vulnerabilities requiring microcode features will never be fixed. On most of these vulnerabilities, you'll have no way to mitigate the issue on a vulnerable system, appart from buying a more recent CPU. Sometimes, you might be able to mitigate the issue by disabling a CPU feature instead (often at the cost of speed). When this is the case, the script will list this as one of the possible mitigations for the vulnerability.
|
||||
|
||||
- The vulnerability is recent, and your CPU has not yet received a microcode update for the vendor. Often, these updates come in batches, and it can take several batches to cover all the supported CPUs.
|
||||
|
||||
In both cases, you can contact your vendor to know whether there'll be an update or not, and if yes, when. For Intel, at the time this FAQ entry was written, such guidance was [available here](https://software.intel.com/content/www/us/en/develop/topics/software-security-guidance/processors-affected-consolidated-product-cpu-model.html).
|
||||
|
||||
## Which rules are governing the support of a CVE in this tool?
|
||||
|
||||
On the early days, it was easy: just Spectre and Meltdown (hence the tool name), because that's all we had. Now that this range of vulnerability is seeing a bunch of newcomers every year, this question is legitimate.
|
||||
|
||||
To stick with this tool's goal, a good indication as to why a CVE should be supported, is when mitigating it requires either kernel modifications, microcode modifications, or both.
|
||||
|
||||
Counter-examples include (non-exhaustive list):
|
||||
|
||||
- [CVE-2019-14615](https://github.com/speed47/spectre-meltdown-checker/issues/340), mitigating this issue is done by updating the Intel driver. This is out of the scope of this tool.
|
||||
- [CVE-2019-15902](https://github.com/speed47/spectre-meltdown-checker/issues/304), this CVE is due to a bad backport in the stable kernel. If the faulty backport was part of the mitigation of another supported CVE, and this bad backport was detectable (without hardcoding kernel versions, see [rule 2](#why-are-those-vulnerabilities-so-different-than-regular-cves)), it might have been added as a bullet point in the concerned CVE's section in the tool. However, this wasn't the case.
|
||||
- The "[Take A Way](https://github.com/speed47/spectre-meltdown-checker/issues/344)" vulnerability, AMD said that they believe this is not a new attack, hence there were no microcode and no kernel modification made. As there is nothing to look for, this is out of the scope of this tool.
|
||||
- [CVE-2020-0550](https://github.com/speed47/spectre-meltdown-checker/issues/347), the vendor thinks this is hardly exploitable in the wild, and as mitigations would be too performance impacting, as a whole the industry decided to not address it. As there is nothing to check for, this is out of the scope of this tool.
|
||||
- [CVE-2020-0551](https://github.com/speed47/spectre-meltdown-checker/issues/348), the industry decided to not address it, as it is believed mitigations for other CVEs render this attack practically hard to make, Intel just released an updated SDK for SGX to help mitigate the issue, but this is out of the scope of this tool.
|
||||
|
||||
Look for the [information](https://github.com/speed47/spectre-meltdown-checker/issues?q=is%3Aissue+is%3Aopen+label%3Ainformation) tag in the issues list for more examples.
|
||||
@@ -1,241 +0,0 @@
|
||||
Spectre & Meltdown Checker
|
||||
==========================
|
||||
|
||||
A self-contained shell script to assess your system's resilience against the several [transient execution](https://en.wikipedia.org/wiki/Transient_execution_CPU_vulnerability) CVEs that were published since early 2018, and give you guidance as to how to mitigate them.
|
||||
|
||||
## CVE list
|
||||
|
||||
CVE | Name | Aliases
|
||||
--- | ---- | -------
|
||||
[CVE-2017-5753](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2017-5753) | Bounds Check Bypass | Spectre V1
|
||||
[CVE-2017-5715](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2017-5715) | Branch Target Injection | Spectre V2
|
||||
[CVE-2017-5754](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2017-5754) | Rogue Data Cache Load | Meltdown
|
||||
[CVE-2018-3640](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2018-3640) | Rogue System Register Read | Variant 3a
|
||||
[CVE-2018-3639](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2018-3639) | Speculative Store Bypass | Variant 4, SSB
|
||||
[CVE-2018-3615](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2018-3615) | L1 Terminal Fault | Foreshadow (SGX)
|
||||
[CVE-2018-3620](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2018-3620) | L1 Terminal Fault | Foreshadow-NG (OS/SMM)
|
||||
[CVE-2018-3646](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2018-3646) | L1 Terminal Fault | Foreshadow-NG (VMM)
|
||||
[CVE-2018-12126](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2018-12126) | Microarchitectural Store Buffer Data Sampling | MSBDS, Fallout
|
||||
[CVE-2018-12130](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2018-12130) | Microarchitectural Fill Buffer Data Sampling | MFBDS, ZombieLoad
|
||||
[CVE-2018-12127](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2018-12127) | Microarchitectural Load Port Data Sampling | MLPDS, RIDL
|
||||
[CVE-2019-11091](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2019-11091) | Microarchitectural Data Sampling Uncacheable Memory | MDSUM, RIDL
|
||||
[CVE-2019-11135](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2019-11135) | TSX Asynchronous Abort | TAA, ZombieLoad V2
|
||||
[CVE-2018-12207](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2018-12207) | Machine Check Exception on Page Size Changes | iTLB Multihit, No eXcuses
|
||||
[CVE-2020-0543](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2020-0543) | Special Register Buffer Data Sampling | SRBDS, CROSSTalk
|
||||
[CVE-2022-40982](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-40982) | Gather Data Sampling | Downfall, GDS
|
||||
[CVE-2023-20569](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2023-20569) | Return Address Security | Inception, SRSO
|
||||
[CVE-2023-20593](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2023-20593) | Cross-Process Information Leak | Zenbleed
|
||||
[CVE-2023-23583](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2023-23583) | Redundant Prefix Issue | Reptar
|
||||
[CVE-2024-36350](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2024-36350) | Transient Scheduler Attack, Store Queue | TSA-SQ
|
||||
[CVE-2024-36357](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2024-36357) | Transient Scheduler Attack, L1 | TSA-L1
|
||||
|
||||
## Am I at risk?
|
||||
|
||||
Depending on your situation, the table below answers whether an attacker in a given position can extract data from a given target.
|
||||
The "Userland → Kernel" column also applies within a VM (VM userland vs. VM kernel), since the same CPU mechanisms are at play regardless of virtualization.
|
||||
|
||||
Vulnerability | Userland → Kernel | Userland → Userland | VM → Host | VM → VM | Mitigation
|
||||
------------ | :---------------: | :-----------------: | :-------: | :-----: | ----------
|
||||
CVE-2017-5753 (Spectre V1) | 💥 | 💥 | 💥 | 💥 | Recompile everything with LFENCE
|
||||
CVE-2017-5715 (Spectre V2) | 💥 | 💥 | 💥 | 💥 | Microcode + kernel update (or retpoline)
|
||||
CVE-2017-5754 (Meltdown) | 💥 | ✅ | ✅ | ✅ | Kernel update
|
||||
CVE-2018-3640 (Variant 3a) | 💥 | ✅ | ✅ | ✅ | Microcode update
|
||||
CVE-2018-3639 (Variant 4, SSB) | ✅ | 💥 | ✅ | ✅ | Microcode + kernel update
|
||||
CVE-2018-3615 (Foreshadow, SGX) | ✅ (3) | ✅ (3) | ✅ (3) | ✅ (3) | Microcode update
|
||||
CVE-2018-3620 (Foreshadow-NG, OS/SMM) | 💥 | ✅ | ✅ | ✅ | Kernel update
|
||||
CVE-2018-3646 (Foreshadow-NG, VMM) | ✅ | ✅ | 💥 | 💥 | Kernel update (or disable EPT/SMT)
|
||||
CVE-2018-12126 (MSBDS, Fallout) | 💥 | 💥 (1) | 💥 | 💥 (1) | Microcode + kernel update
|
||||
CVE-2018-12130 (MFBDS, ZombieLoad) | 💥 | 💥 (1) | 💥 | 💥 (1) | Microcode + kernel update
|
||||
CVE-2018-12127 (MLPDS, RIDL) | 💥 | 💥 (1) | 💥 | 💥 (1) | Microcode + kernel update
|
||||
CVE-2019-11091 (MDSUM, RIDL) | 💥 | 💥 (1) | 💥 | 💥 (1) | Microcode + kernel update
|
||||
CVE-2019-11135 (TAA, ZombieLoad V2) | 💥 | 💥 (1) | 💥 | 💥 (1) | Microcode + kernel update
|
||||
CVE-2018-12207 (iTLB Multihit, No eXcuses) | ✅ | ✅ | ☠️ | ✅ | Hypervisor update (or disable hugepages)
|
||||
CVE-2020-0543 (SRBDS, CROSSTalk) | 💥 (2) | 💥 (2) | 💥 (2) | 💥 (2) | Microcode + kernel update
|
||||
CVE-2022-40982 (Downfall, GDS) | 💥 | 💥 | 💥 | 💥 | Microcode update (or disable AVX)
|
||||
CVE-2023-20569 (Inception, SRSO) | 💥 | ✅ | 💥 | ✅ | Microcode + kernel update
|
||||
CVE-2023-20593 (Zenbleed) | 💥 | 💥 | 💥 | 💥 | Microcode update (or kernel workaround)
|
||||
CVE-2023-23583 (Reptar) | ☠️ | ☠️ | ☠️ | ☠️ | Microcode update
|
||||
CVE-2024-36350 (TSA-SQ) | 💥 | 💥 (1) | 💥 | 💥 (1) | Microcode + kernel update
|
||||
CVE-2024-36357 (TSA-L1) | 💥 | 💥 (1) | 💥 | 💥 (1) | Microcode + kernel update
|
||||
|
||||
> 💥 Data can be leaked across this boundary.
|
||||
|
||||
> ✅ Not affected in this scenario.
|
||||
|
||||
> ☠️ Denial of service (system crash or unpredictable behavior), no data leak.
|
||||
|
||||
> (1) Cross-process leakage requires SMT (Hyper-Threading) to be active — attacker and victim must share a physical core.
|
||||
|
||||
> (2) Only leaks RDRAND/RDSEED output, not arbitrary memory; still allows recovering cryptographic material from any victim.
|
||||
|
||||
> (3) CVE-2018-3615 (Foreshadow SGX) inverts the normal trust model: the OS reads SGX enclave data. It is irrelevant unless the system runs SGX enclaves, and the attacker must already have OS-level access.
|
||||
|
||||
## Detailed CVE descriptions
|
||||
|
||||
<details>
|
||||
<summary>Unfold for more detailed CVE descriptions</summary>
|
||||
|
||||
**CVE-2017-5753 — Bounds Check Bypass (Spectre Variant 1)**
|
||||
|
||||
An attacker can train the branch predictor to mispredict a bounds check, causing the CPU to speculatively access out-of-bounds memory. This affects all software, including the kernel, because any conditional bounds check can potentially be exploited. Mitigation requires recompiling software and the kernel with a compiler that inserts LFENCE instructions (or equivalent speculation barriers like `array_index_nospec`) at the proper positions. The performance impact is negligible because the barriers only apply to specific, targeted code patterns.
|
||||
|
||||
**CVE-2017-5715 — Branch Target Injection (Spectre Variant 2)**
|
||||
|
||||
An attacker can poison the Branch Target Buffer (BTB) to redirect speculative execution of indirect branches in the kernel, leaking kernel memory. Two mitigation strategies exist: (1) microcode updates providing IBRS (Indirect Branch Restricted Speculation), which flushes branch predictor state on privilege transitions — this has a medium to high performance cost, especially on older hardware; or (2) retpoline, a compiler technique that replaces indirect branches with a construct the speculator cannot exploit — this has a lower performance cost but requires recompiling the kernel and sensitive software.
|
||||
|
||||
**CVE-2017-5754 — Rogue Data Cache Load (Meltdown)**
|
||||
|
||||
On affected Intel processors, a user process can speculatively read kernel memory despite lacking permission. The CPU eventually raises a fault, but the data leaves observable traces in the cache. Mitigation is entirely kernel-side: Page Table Isolation (PTI/KPTI) unmaps most kernel memory from user-space page tables, so there is nothing to speculatively read. The performance impact is low to medium, mainly from the increased TLB pressure caused by switching page tables on every kernel entry and exit.
|
||||
|
||||
**CVE-2018-3640 — Rogue System Register Read (Variant 3a)**
|
||||
|
||||
Similar to Meltdown but targeting system registers: an unprivileged process can speculatively read privileged system register values (such as Model-Specific Registers) and exfiltrate them via a side channel. Mitigation requires a microcode update only — no kernel changes are needed. Performance impact is negligible.
|
||||
|
||||
**CVE-2018-3639 — Speculative Store Bypass (Variant 4)**
|
||||
|
||||
The CPU may speculatively load a value from memory before a preceding store to the same address completes, reading stale data. This primarily affects software using JIT compilation (e.g. JavaScript engines, eBPF), where an attacker can craft code that exploits the store-to-load dependency. No known exploitation against the kernel itself has been demonstrated. Mitigation requires a microcode update (providing the SSBD mechanism) plus a kernel update that allows affected software to opt in to the protection via prctl(). The performance impact is low to medium, depending on how frequently the mitigation is activated.
|
||||
|
||||
**CVE-2018-3615 — L1 Terminal Fault (Foreshadow, SGX)**
|
||||
|
||||
The original Foreshadow attack targets Intel SGX enclaves. When a page table entry's Present bit is cleared, the CPU may still speculatively use the physical address in the entry to fetch data from the L1 cache, bypassing SGX protections. An attacker can extract secrets (attestation keys, sealed data) from SGX enclaves. Mitigation requires a microcode update that includes modifications to SGX behavior. Performance impact is negligible.
|
||||
|
||||
**CVE-2018-3620 — L1 Terminal Fault (Foreshadow-NG, OS/SMM)**
|
||||
|
||||
A generalization of Foreshadow beyond SGX: unprivileged user-space code can exploit the same L1TF mechanism to read kernel memory or System Management Mode (SMM) memory. Mitigation requires a kernel update that implements PTE inversion — marking non-present page table entries with invalid physical addresses so the L1 cache cannot contain useful data at those addresses. Performance impact is negligible because PTE inversion is a one-time change to the page table management logic with no runtime overhead.
|
||||
|
||||
**CVE-2018-3646 — L1 Terminal Fault (Foreshadow-NG, VMM)**
|
||||
|
||||
A guest VM can exploit L1TF to read memory belonging to the host or other guests, because the hypervisor's page tables may have non-present entries pointing to valid host physical addresses still resident in L1. Mitigation options include: flushing the L1 data cache on every VM entry (via a kernel update providing L1d flush support), disabling Extended Page Tables (EPT), or disabling Hyper-Threading (SMT) to prevent a sibling thread from refilling the L1 cache during speculation. The performance impact ranges from low to significant depending on the chosen mitigation, with L1d flushing on VM entry being the most practical but still measurable on VM-heavy workloads.
|
||||
|
||||
**CVE-2018-12126 — Microarchitectural Store Buffer Data Sampling (MSBDS, Fallout)**
|
||||
|
||||
**CVE-2018-12130 — Microarchitectural Fill Buffer Data Sampling (MFBDS, ZombieLoad)**
|
||||
|
||||
**CVE-2018-12127 — Microarchitectural Load Port Data Sampling (MLPDS, RIDL)**
|
||||
|
||||
**CVE-2019-11091 — Microarchitectural Data Sampling Uncacheable Memory (MDSUM, RIDL)**
|
||||
|
||||
These four CVEs are collectively known as "MDS" (Microarchitectural Data Sampling) vulnerabilities. They exploit different CPU internal buffers — store buffer, fill buffer, load ports, and uncacheable memory paths — that can leak recently accessed data across privilege boundaries during speculative execution. An unprivileged attacker can observe data recently processed by the kernel or other processes. Mitigation requires a microcode update (providing the MD_CLEAR mechanism) plus a kernel update that uses VERW to clear affected buffers on privilege transitions. Disabling Hyper-Threading (SMT) provides additional protection because sibling threads share these buffers. The performance impact is low to significant, depending on the frequency of kernel transitions and whether SMT is disabled.
|
||||
|
||||
**CVE-2019-11135 — TSX Asynchronous Abort (TAA, ZombieLoad V2)**
|
||||
|
||||
On CPUs with Intel TSX, a transactional abort can leave data from the line fill buffers in a state observable through side channels, similar to the MDS vulnerabilities but triggered through TSX. Mitigation requires a microcode update plus kernel support to either clear affected buffers or disable TSX entirely (via the TSX_CTRL MSR). The performance impact is low to significant, similar to MDS, with the option to eliminate the attack surface entirely by disabling TSX at the cost of losing transactional memory support.
|
||||
|
||||
**CVE-2018-12207 — Machine Check Exception on Page Size Changes (iTLB Multihit, No eXcuses)**
|
||||
|
||||
A malicious guest VM can trigger a machine check exception (MCE) — crashing the entire host — by creating specific conditions in the instruction TLB involving page size changes. This is a denial-of-service vulnerability affecting hypervisors running untrusted guests. Mitigation requires either disabling hugepage use in the hypervisor or updating the hypervisor to avoid the problematic iTLB configurations. The performance impact ranges from low to significant depending on the approach: disabling hugepages can substantially impact memory-intensive workloads.
|
||||
|
||||
**CVE-2020-0543 — Special Register Buffer Data Sampling (SRBDS, CROSSTalk)**
|
||||
|
||||
Certain special CPU instructions (RDRAND, RDSEED, EGETKEY) read data through a shared staging buffer that is accessible across all cores via speculative execution. An attacker running code on any core can observe the output of these instructions from a victim on a different core, including extracting cryptographic keys from SGX enclaves (a complete ECDSA key was demonstrated). This is notable as one of the first cross-core speculative execution attacks. Mitigation requires a microcode update that serializes access to the staging buffer, plus a kernel update to manage the mitigation. Performance impact is low, mainly affecting workloads that heavily use RDRAND/RDSEED.
|
||||
|
||||
**CVE-2022-40982 — Gather Data Sampling (GDS, Downfall)**
|
||||
|
||||
The AVX GATHER instructions can leak data from previously used vector registers across privilege boundaries through the shared gather data buffer. This affects any software using AVX2 or AVX-512 on vulnerable Intel processors. Mitigation is provided by a microcode update that clears the gather buffer, or alternatively by disabling the AVX feature entirely. Performance impact is negligible for most workloads but can be significant (up to 50%) for AVX-heavy applications such as HPC and AI inference.
|
||||
|
||||
**CVE-2023-20569 — Return Address Security (Inception, SRSO)**
|
||||
|
||||
On AMD Zen 1 through Zen 4 processors, an attacker can manipulate the return address predictor to redirect speculative execution on return instructions, leaking kernel memory. Mitigation requires both a kernel update (providing SRSO safe-return sequences or IBPB-on-entry) and a microcode update (providing SBPB on Zen 3/4, or IBPB support on Zen 1/2 — which additionally requires SMT to be disabled). Performance impact ranges from low to significant depending on the chosen mitigation and CPU generation.
|
||||
|
||||
**CVE-2023-20593 — Cross-Process Information Leak (Zenbleed)**
|
||||
|
||||
A bug in AMD Zen 2 processors causes the VZEROUPPER instruction to incorrectly zero register files during speculative execution, leaving stale data from other processes observable in vector registers. This can leak data across any privilege boundary, including from the kernel and other processes, at rates up to 30 KB/s per core. Mitigation is available either through a microcode update that fixes the bug, or through a kernel workaround that sets the FP_BACKUP_FIX bit (bit 9) in the DE_CFG MSR, disabling the faulty optimization. Either approach alone is sufficient. Performance impact is negligible.
|
||||
|
||||
**CVE-2023-23583 — Redundant Prefix Issue (Reptar)**
|
||||
|
||||
A bug in Intel processors causes unexpected behavior when executing instructions with specific redundant REX prefixes. Depending on the circumstances, this can result in a system crash (MCE), unpredictable behavior, or potentially privilege escalation. Any software running on an affected CPU can trigger the bug. Mitigation requires a microcode update. Performance impact is low.
|
||||
|
||||
**CVE-2024-36350 — Transient Scheduler Attack, Store Queue (TSA-SQ)**
|
||||
|
||||
On AMD Zen 3 and Zen 4 processors, the CPU's transient scheduler may speculatively retrieve stale data from the store queue during certain timing windows, allowing an attacker to infer data from previous store operations across privilege boundaries. The attack can also leak data between SMT sibling threads. Mitigation requires both a microcode update (exposing the VERW_CLEAR capability) and a kernel update (CONFIG_MITIGATION_TSA, Linux 6.16+) that uses the VERW instruction to clear CPU buffers on user/kernel transitions and before VMRUN. The kernel also clears buffers on idle when SMT is active. Performance impact is low to medium.
|
||||
|
||||
**CVE-2024-36357 — Transient Scheduler Attack, L1 (TSA-L1)**
|
||||
|
||||
On AMD Zen 3 and Zen 4 processors, the CPU's transient scheduler may speculatively retrieve stale data from the L1 data cache during certain timing windows, allowing an attacker to infer data in the L1D cache across privilege boundaries. Mitigation requires the same microcode and kernel updates as TSA-SQ: a microcode update exposing VERW_CLEAR and a kernel update (CONFIG_MITIGATION_TSA, Linux 6.16+) that clears CPU buffers via VERW on privilege transitions. Performance impact is low to medium.
|
||||
|
||||
</details>
|
||||
|
||||
## Scope
|
||||
|
||||
Supported operating systems:
|
||||
- Linux (all versions, flavors and distros)
|
||||
- FreeBSD, NetBSD, DragonFlyBSD and derivatives (others BSDs are [not supported](FAQ.md#which-bsd-oses-are-supported))
|
||||
|
||||
For Linux systems, the tool will detect mitigations, including backported non-vanilla patches, regardless of the advertised kernel version number and the distribution (such as Debian, Ubuntu, CentOS, RHEL, Fedora, openSUSE, Arch, ...), it also works if you've compiled your own kernel. More information [here](FAQ.md#how-does-this-script-work).
|
||||
|
||||
Other operating systems such as MacOS, Windows, ESXi, etc. [will never be supported](FAQ.md#why-is-my-os-not-supported).
|
||||
|
||||
Supported architectures:
|
||||
- `x86` (32 bits)
|
||||
- `amd64`/`x86_64` (64 bits)
|
||||
- `ARM` and `ARM64`
|
||||
- other architectures will work, but mitigations (if they exist) might not always be detected
|
||||
|
||||
## Frequently Asked Questions (FAQ)
|
||||
|
||||
What is the purpose of this tool? Why was it written? How can it be useful to me? How does it work? What can I expect from it?
|
||||
|
||||
All these questions (and more) have detailed answers in the [FAQ](FAQ.md), please have a look!
|
||||
|
||||
## Running the script
|
||||
|
||||
### Direct way (recommended)
|
||||
|
||||
- Get the latest version of the script using `curl` *or* `wget`
|
||||
|
||||
```bash
|
||||
curl -L https://meltdown.ovh -o spectre-meltdown-checker.sh
|
||||
wget https://meltdown.ovh -O spectre-meltdown-checker.sh
|
||||
```
|
||||
|
||||
- Inspect the script. You never blindly run scripts you downloaded from the Internet, do you?
|
||||
|
||||
```bash
|
||||
vim spectre-meltdown-checker.sh
|
||||
```
|
||||
|
||||
- When you're ready, run the script as root
|
||||
|
||||
```bash
|
||||
chmod +x spectre-meltdown-checker.sh
|
||||
sudo ./spectre-meltdown-checker.sh
|
||||
```
|
||||
|
||||
### Using a docker container
|
||||
|
||||
<details>
|
||||
<summary>Unfold for instructions</summary>
|
||||
|
||||
Using `docker compose`:
|
||||
|
||||
```shell
|
||||
docker compose build
|
||||
docker compose run --rm spectre-meltdown-checker
|
||||
```
|
||||
|
||||
Note that on older versions of docker, `docker-compose` is a separate command, so you might
|
||||
need to replace the two `docker compose` occurences above by `docker-compose`.
|
||||
|
||||
Using `docker build` directly:
|
||||
|
||||
```shell
|
||||
docker build -t spectre-meltdown-checker .
|
||||
docker run --rm --privileged -v /boot:/boot:ro -v /dev/cpu:/dev/cpu:ro -v /lib/modules:/lib/modules:ro spectre-meltdown-checker
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
## Example of script output
|
||||
|
||||
- Intel Haswell CPU running under Ubuntu 16.04 LTS
|
||||
|
||||

|
||||
|
||||
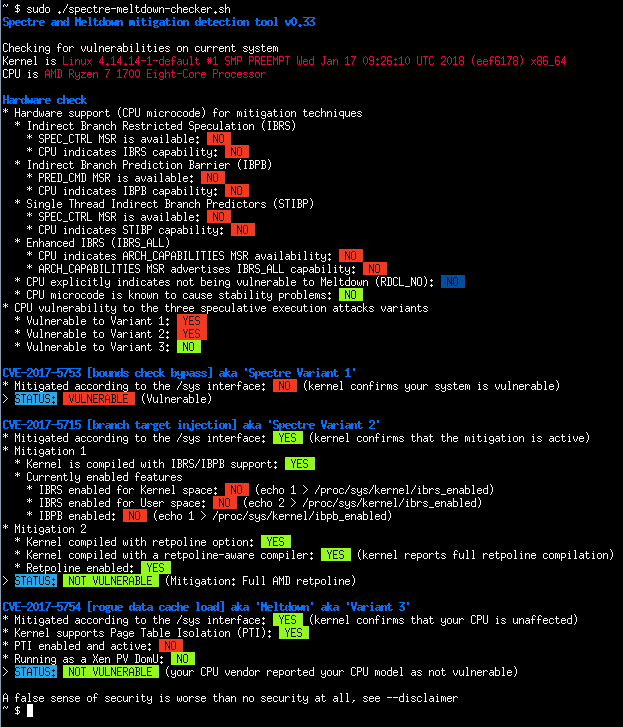
- AMD Ryzen running under OpenSUSE Tumbleweed
|
||||
|
||||
|
||||
|
||||
- Batch mode (JSON flavor)
|
||||
|
||||

|
||||
|
||||
@@ -1,13 +0,0 @@
|
||||
services:
|
||||
spectre-meltdown-checker:
|
||||
build:
|
||||
context: ./
|
||||
dockerfile: ./Dockerfile
|
||||
image: spectre-meltdown-checker:latest
|
||||
container_name: spectre-meltdown-checker
|
||||
privileged: true
|
||||
network_mode: none
|
||||
volumes:
|
||||
- /boot:/boot:ro
|
||||
- /dev/cpu:/dev/cpu:ro
|
||||
- /lib/modules:/lib/modules:ro
|
||||
@@ -0,0 +1,266 @@
|
||||
# Daily transient-execution vulnerability scan — classification step
|
||||
|
||||
You are a scheduled agent running inside a GitHub Actions job. A preceding
|
||||
workflow step has already fetched all configured sources, applied HTTP
|
||||
conditional caching, deduped against prior state, and written the pre-filtered
|
||||
list of new items to `new_items.json`. Your only job is to classify each item.
|
||||
|
||||
## Scope — read the authoritative docs before classifying
|
||||
|
||||
The project's own docs define what belongs in this tool. **Read them early
|
||||
in the run** (once per run; Claude caches, these don't change daily):
|
||||
|
||||
1. **`./checker/DEVELOPMENT.md`** — "Project Mission" section. What the
|
||||
script does, what it explicitly does not do, its platform scope
|
||||
(Linux + BSD on x86/amd64/ARM/ARM64).
|
||||
2. **`./checker/dist/doc/FAQ.md`** — the section titled
|
||||
_"Which rules are governing the support of a CVE in this tool?"_.
|
||||
This is the **operative test**:
|
||||
> A CVE belongs in scope when mitigating it requires **kernel
|
||||
> modifications, microcode modifications, or both** — and those
|
||||
> modifications are **detectable** by this tool (no hardcoded kernel
|
||||
> versions; look for actual mechanisms).
|
||||
3. **`./checker/dist/doc/UNSUPPORTED_CVE_LIST.md`** — explicit list of
|
||||
CVEs ruled out, grouped by reason:
|
||||
- _Already covered by a parent CVE check_ (e.g. SpectreRSB ⊂ Spectre V2).
|
||||
- _No detectable kernel/microcode mitigation_ (vendor won't fix, GPU
|
||||
driver-only, userspace-only, etc.).
|
||||
- _Not a transient / speculative execution vulnerability at all_.
|
||||
|
||||
Match incoming items against those exclusion patterns. If a CVE is a
|
||||
subvariant of a covered parent, or has no kernel/microcode mitigation
|
||||
this tool can detect, or is simply not a transient-execution issue, it
|
||||
is **unrelated** — not `tocheck`. Out-of-scope items with zero ambiguity
|
||||
should not linger in the `tocheck` backlog.
|
||||
|
||||
In-scope shortlist (for quick reference; the README's CVE table is the
|
||||
authoritative source): Spectre v1/v2/v4, Meltdown, Foreshadow/L1TF,
|
||||
MDS (ZombieLoad/RIDL/Fallout), TAA, SRBDS, iTLB Multihit, MMIO Stale
|
||||
Data, Retbleed, Zenbleed, Downfall (GDS), Inception/SRSO, DIV0, Reptar,
|
||||
RFDS, ITS, TSA-SQ/TSA-L1, VMScape, BPI, FP-DSS — and similar
|
||||
microarchitectural side-channel / speculative-execution issues on
|
||||
Intel / AMD / ARM CPUs with a detectable mitigation.
|
||||
|
||||
Explicitly out of scope: generic software CVEs, GPU driver bugs,
|
||||
networking stacks, filesystem bugs, userspace crypto issues, unrelated
|
||||
kernel subsystems, CPU bugs that the industry has decided not to mitigate
|
||||
(nothing for the tool to check), and CVEs fixed by userspace/SDK updates
|
||||
only.
|
||||
|
||||
## Inputs
|
||||
|
||||
- `new_items.json` — shape:
|
||||
|
||||
```json
|
||||
{
|
||||
"scan_date": "2026-04-18T14:24:43+00:00",
|
||||
"window_cutoff": "2026-04-17T13:24:43+00:00",
|
||||
"per_source": { "phoronix": {"status": 200, "new": 2, "total_in_feed": 75} },
|
||||
"items": [
|
||||
{
|
||||
"source": "phoronix",
|
||||
"stable_id": "CVE-2026-1234",
|
||||
"title": "...",
|
||||
"permalink": "https://...",
|
||||
"guid": "...",
|
||||
"published_at": "2026-04-18T05:00:00+00:00",
|
||||
"extracted_cves": ["CVE-2026-1234"],
|
||||
"vendor_ids": [],
|
||||
"snippet": "first 400 chars of description, tags stripped"
|
||||
}
|
||||
],
|
||||
"reconsider": [
|
||||
{
|
||||
"canonical_id": "INTEL-SA-00145",
|
||||
"current_bucket": "toimplement",
|
||||
"title": "Lazy FP State Restore",
|
||||
"sources": ["intel-psirt"],
|
||||
"urls": ["https://www.intel.com/.../intel-sa-00145.html"],
|
||||
"extracted_cves": [],
|
||||
"first_seen": "2026-04-19T09:41:44+00:00"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
- `items` are fresh observations from today's fetch: already inside the
|
||||
time window and not yet present in state under any alt-ID.
|
||||
- `reconsider` holds existing `toimplement`/`tocheck` entries from state,
|
||||
submitted for re-review each run (see the "Reconsideration" section
|
||||
below). On days where both arrays are empty, write stub output files
|
||||
with `(no new items in this window)`.
|
||||
|
||||
- `./checker/` is a checkout of the **`test`** branch of this repo (the
|
||||
development branch where coded-but-unreleased CVE checks live). This is
|
||||
the source of truth for whether a CVE is already covered. Grep this
|
||||
directory — not the working directory root, which only holds the
|
||||
vuln-watch scripts and has no checker code.
|
||||
|
||||
## Classification rules
|
||||
|
||||
For each item in `items`, pick exactly one bucket:
|
||||
|
||||
- **toimplement** — clearly in-scope per the FAQ test (kernel/microcode
|
||||
mitigation exists AND is detectable by this tool), and **not already
|
||||
covered** by `./checker/`. Verify the second half: grep `./checker/`
|
||||
for each `extracted_cves` entry *and* for any codename in the title
|
||||
(e.g., "FP-DSS", "Inception"). If either matches, the right bucket is
|
||||
`unrelated` (already covered) or `tocheck` (maintainer should confirm
|
||||
whether an existing check handles the new variant).
|
||||
- **tocheck** — there is a **specific question a maintainer must answer**
|
||||
before this can be filed anywhere else. Examples:
|
||||
- Ambiguity about whether an existing check (e.g. parent Spectre V2)
|
||||
transitively covers this new sub-variant, or whether a fresh entry
|
||||
is warranted.
|
||||
- Embedded-only ARM SKU and it's unclear if the tool's ARM support
|
||||
reaches that class of SKU.
|
||||
- Vendor advisory published without a CVE ID yet, but the vuln looks
|
||||
in-scope; revisit once the CVE is assigned.
|
||||
- Contradictory statements across sources about whether a mitigation
|
||||
is detectable (kernel-patch vs. userspace-only vs. microcode).
|
||||
|
||||
**Do NOT use `tocheck` as a catch-all** for "I'm not sure". Most items
|
||||
have a clear answer once you consult UNSUPPORTED_CVE_LIST.md and the
|
||||
FAQ rule. If you can articulate the specific question a maintainer
|
||||
needs to answer — `tocheck`. If the only reason is "maybe?" — it's
|
||||
`unrelated`.
|
||||
|
||||
- **unrelated** — everything else. Including:
|
||||
- Matches a pattern in UNSUPPORTED_CVE_LIST.md (subvariant of covered
|
||||
parent, no detectable mitigation, not transient-execution).
|
||||
- Fails the FAQ rule (userspace-only fix, driver update, industry
|
||||
decided not to mitigate).
|
||||
- Non-CPU security topic (kernel filesystem bug, network stack, crypto
|
||||
library, GPU driver, compiler flag change, distro release notes).
|
||||
|
||||
**Tie-breakers** (note the direction — this used to bias the other way):
|
||||
- Prefer `unrelated` over `tocheck` when the item matches a category in
|
||||
UNSUPPORTED_CVE_LIST.md or plainly fails the FAQ rule. Growing the
|
||||
`tocheck` backlog with obvious-unrelateds wastes human time more than
|
||||
a confident `unrelated` does.
|
||||
- Prefer `tocheck` over `toimplement` when the CVE is still "reserved" /
|
||||
"pending" — false positives in `toimplement` create phantom work.
|
||||
|
||||
`WebFetch` is available for resolving genuine `tocheck` ambiguity.
|
||||
Budget: **3 follow-ups per run total**. Do not use it for items you
|
||||
already plan to file as `unrelated` or `toimplement`.
|
||||
|
||||
## Reconsideration rules (for `reconsider` entries)
|
||||
|
||||
Each `reconsider` entry is an item *already* in state under `current_bucket`
|
||||
= `toimplement` or `tocheck`, from a prior run. Re-examine it against the
|
||||
**current** `./checker/` tree and the scope docs above. This pass is the
|
||||
right place to prune the `tocheck` backlog: prior runs (before these
|
||||
scope docs were wired in) may have hedged on items that now have a clear
|
||||
`unrelated` answer — demote them aggressively. You may:
|
||||
|
||||
- **Demote** `toimplement` → `tocheck` or `unrelated` if the checker now
|
||||
covers the CVE/codename (grep confirms), or if reinterpreting the
|
||||
advisory shows it's out of scope.
|
||||
- **Demote** `tocheck` → `unrelated` if new context settles the ambiguity
|
||||
as out-of-scope.
|
||||
- **Promote** `tocheck` → `toimplement` if you now have firm evidence it's
|
||||
a real, in-scope, not-yet-covered CVE.
|
||||
- **Leave it unchanged** (same bucket) — emit a record anyway; it's cheap
|
||||
and documents that the reconsideration happened today.
|
||||
- **Reassign the canonical ID** — if a CVE has since been assigned to a
|
||||
vendor advisory (e.g., an INTEL-SA that previously had no CVE), put the
|
||||
CVE in `extracted_cves` and use it as the new `canonical_id`. The merge
|
||||
step will rekey the record under the CVE and keep the old ID as an alias.
|
||||
|
||||
For every reconsider record you emit, set `"reconsider": true` in its
|
||||
classification entry — this tells the merge step to **overwrite** the
|
||||
stored bucket (including demotions), not just promote.
|
||||
|
||||
## Outputs
|
||||
|
||||
Compute `TODAY` = the `YYYY-MM-DD` prefix of `scan_date`. Write three files at
|
||||
the repo root, overwriting if present:
|
||||
|
||||
- `watch_${TODAY}_toimplement.md`
|
||||
- `watch_${TODAY}_tocheck.md`
|
||||
- `watch_${TODAY}_unrelated.md`
|
||||
|
||||
These delta files cover the **`items`** array only — they answer "what
|
||||
did today's fetch surface". Reconsider decisions update state (and surface
|
||||
in the `current_*.md` snapshots the merge step rewrites); don't duplicate
|
||||
them here.
|
||||
|
||||
Each file uses level-2 headers per source short-name, then one bullet per
|
||||
item: the stable ID, the permalink, and 1–2 sentences of context.
|
||||
|
||||
```markdown
|
||||
## oss-sec
|
||||
- **CVE-2026-1234** — https://www.openwall.com/lists/oss-security/2026/04/18/3
|
||||
New Intel transient-execution bug "Foo"; affects Redwood Cove cores.
|
||||
Not yet covered (grepped CVE-2026-1234 and "Foo" — no matches).
|
||||
```
|
||||
|
||||
If a bucket has no items, write `(no new items in this window)`.
|
||||
|
||||
Append the following block to the **tocheck** file (creating it if
|
||||
otherwise empty):
|
||||
|
||||
```markdown
|
||||
## Run summary
|
||||
- scan_date: <value>
|
||||
- per-source counts (from per_source): ...
|
||||
- fetch failures (status != 200/304): ...
|
||||
- total classified this run: toimplement=<n>, tocheck=<n>, unrelated=<n>
|
||||
- reconsidered: <n> entries re-reviewed; <list any bucket transitions, e.g.
|
||||
"CVE-2018-3665: toimplement -> tocheck (now covered at src/vulns/...)">,
|
||||
or "no transitions" if every reconsider kept its existing bucket.
|
||||
```
|
||||
|
||||
## `classifications.json` — required side-channel for the merge step
|
||||
|
||||
Also write `classifications.json` at the repo root. It is a JSON array, one
|
||||
record per item in `new_items.json.items`:
|
||||
|
||||
```json
|
||||
[
|
||||
{
|
||||
"stable_id": "CVE-2026-1234",
|
||||
"canonical_id": "CVE-2026-1234",
|
||||
"bucket": "toimplement",
|
||||
"extracted_cves": ["CVE-2026-1234"],
|
||||
"sources": ["phoronix"],
|
||||
"urls": ["https://www.phoronix.com/news/..."]
|
||||
}
|
||||
]
|
||||
```
|
||||
|
||||
Rules:
|
||||
|
||||
- One record per input item (`items` + `reconsider`). For items, use the
|
||||
same `stable_id` as in `new_items.json`. For reconsider entries, use the
|
||||
entry's `canonical_id` from state as the record's `stable_id`.
|
||||
- `canonical_id`: prefer the first `extracted_cves` entry if any; otherwise
|
||||
the item's `stable_id`. **Use the same `canonical_id` for multiple items
|
||||
that are really the same CVE from different sources** — the merge step
|
||||
will collapse them into one entry and add alias rows automatically.
|
||||
- **Populate `extracted_cves` / `canonical_id` from context when the feed
|
||||
didn't.** If the title, body, or a well-known transient-execution codename
|
||||
mapping lets you identify a CVE the feed didn't emit (e.g., "Lazy FP
|
||||
State Restore" → `CVE-2018-3665`, "LazyFP" → same, "FP-DSS" → whatever
|
||||
CVE AMD/Intel assigned), put the CVE in `extracted_cves` and use it as
|
||||
`canonical_id`. This prevents Intel's CVE-less listing entries from
|
||||
creating orphan `INTEL-SA-NNNNN` records in the backlog.
|
||||
- `sources` / `urls`: arrays; default to the item's own single source and
|
||||
permalink if you didn't enrich further.
|
||||
- **`reconsider: true`** — set on every record that corresponds to an
|
||||
input from the `reconsider` array. The merge step uses this flag to
|
||||
overwrite the stored bucket instead of merging by "strongest wins" —
|
||||
this is what enables demotions.
|
||||
- If both `items` and `reconsider` are empty, write `[]`.
|
||||
|
||||
## Guardrails
|
||||
|
||||
- Do NOT modify any repo source code. Only write the four output files.
|
||||
- Do NOT create commits, branches, or PRs.
|
||||
- Do NOT call tools that post externally (Slack, GitHub comments, issues, …).
|
||||
- Do NOT re-fetch the RSS/HTML sources — that was the prior step's job.
|
||||
`WebFetch` is only for drilling into a specific advisory/article URL to
|
||||
resolve a `tocheck` ambiguity (budget 3).
|
||||
- If total runtime exceeds 10 minutes, finish what you have, write partial
|
||||
outputs (+ a note in the tocheck run summary), and exit cleanly.
|
||||
@@ -0,0 +1,570 @@
|
||||
#!/usr/bin/env python3
|
||||
"""Fetch all configured sources, dedup against state/seen.json, emit new_items.json.
|
||||
|
||||
Writes updated per-source HTTP cache metadata (etag, last_modified, hwm_*) back
|
||||
into state/seen.json. Does NOT touch state.seen / state.aliases — that is the
|
||||
merge step's job, after Claude has classified the new items.
|
||||
|
||||
Usage:
|
||||
SCAN_DATE=2026-04-18T14:24:43Z python -m scripts.vuln_watch.fetch_and_diff
|
||||
"""
|
||||
from __future__ import annotations
|
||||
|
||||
import argparse
|
||||
import datetime
|
||||
import gzip
|
||||
import json
|
||||
import os
|
||||
import pathlib
|
||||
import re
|
||||
import sys
|
||||
import urllib.error
|
||||
import urllib.parse
|
||||
import urllib.request
|
||||
from typing import Any, Iterable
|
||||
|
||||
import feedparser # type: ignore[import-untyped]
|
||||
|
||||
from .sources import REQUEST_TIMEOUT, SOURCES, Source, USER_AGENT
|
||||
from . import state
|
||||
|
||||
|
||||
CVE_RE = re.compile(r"CVE-\d{4}-\d{4,7}")
|
||||
DEFAULT_WINDOW_HOURS = 25
|
||||
DEFAULT_RECONSIDER_AGE_DAYS = 7
|
||||
MAX_ITEMS_PER_FEED = 200
|
||||
SNIPPET_MAX = 400
|
||||
NEW_ITEMS_PATH = pathlib.Path("new_items.json")
|
||||
|
||||
|
||||
def parse_iso(ts: str | None) -> datetime.datetime | None:
|
||||
if not ts:
|
||||
return None
|
||||
try:
|
||||
return datetime.datetime.fromisoformat(ts.replace("Z", "+00:00"))
|
||||
except ValueError:
|
||||
return None
|
||||
|
||||
|
||||
def now_from_scan_date(scan_date: str) -> datetime.datetime:
|
||||
dt = parse_iso(scan_date)
|
||||
if dt is None:
|
||||
dt = datetime.datetime.now(datetime.timezone.utc)
|
||||
return dt
|
||||
|
||||
|
||||
def conditional_get(
|
||||
url: str,
|
||||
etag: str | None,
|
||||
last_modified: str | None,
|
||||
user_agent: str = USER_AGENT,
|
||||
) -> tuple[int | str, bytes | None, str | None, str | None]:
|
||||
"""Perform a conditional GET.
|
||||
|
||||
Returns (status, body, new_etag, new_last_modified).
|
||||
|
||||
status is:
|
||||
- 200 with body on success
|
||||
- 304 with body=None when unchanged
|
||||
- an int HTTP error code on server-side errors
|
||||
- a string describing a network/transport failure
|
||||
"""
|
||||
req = urllib.request.Request(url, headers={
|
||||
"User-Agent": user_agent,
|
||||
# AMD's CDN stalls on non-gzip clients; asking for gzip speeds up
|
||||
# every source and is strictly beneficial (we decompress locally).
|
||||
"Accept-Encoding": "gzip",
|
||||
})
|
||||
if etag:
|
||||
req.add_header("If-None-Match", etag)
|
||||
if last_modified:
|
||||
req.add_header("If-Modified-Since", last_modified)
|
||||
try:
|
||||
with urllib.request.urlopen(req, timeout=REQUEST_TIMEOUT) as resp:
|
||||
body = resp.read()
|
||||
if resp.headers.get("Content-Encoding", "").lower() == "gzip":
|
||||
try:
|
||||
body = gzip.decompress(body)
|
||||
except OSError:
|
||||
pass # server lied about encoding; use as-is
|
||||
return (
|
||||
resp.status,
|
||||
body,
|
||||
resp.headers.get("ETag"),
|
||||
resp.headers.get("Last-Modified"),
|
||||
)
|
||||
except urllib.error.HTTPError as e:
|
||||
if e.code == 304:
|
||||
return (304, None, etag, last_modified)
|
||||
return (e.code, None, etag, last_modified)
|
||||
except (urllib.error.URLError, TimeoutError, OSError) as e:
|
||||
return (f"network:{type(e).__name__}", None, etag, last_modified)
|
||||
|
||||
|
||||
def extract_cves(text: str) -> list[str]:
|
||||
seen: set[str] = set()
|
||||
out: list[str] = []
|
||||
for m in CVE_RE.findall(text or ""):
|
||||
if m not in seen:
|
||||
seen.add(m)
|
||||
out.append(m)
|
||||
return out
|
||||
|
||||
|
||||
def extract_vendor_ids(text: str, patterns: Iterable[str]) -> list[str]:
|
||||
seen: set[str] = set()
|
||||
out: list[str] = []
|
||||
for p in patterns:
|
||||
for m in re.findall(p, text or ""):
|
||||
if m not in seen:
|
||||
seen.add(m)
|
||||
out.append(m)
|
||||
return out
|
||||
|
||||
|
||||
def pick_stable_id(vendor_ids: list[str], cves: list[str], guid: str, link: str) -> str:
|
||||
"""Pick canonical-ish stable ID: vendor advisory → CVE → guid → permalink.
|
||||
|
||||
CVE is preferred over guid/URL so that the same CVE seen via different
|
||||
feeds collapses on its stable_id alone (in addition to the alias map).
|
||||
"""
|
||||
if vendor_ids:
|
||||
return vendor_ids[0]
|
||||
if cves:
|
||||
return cves[0]
|
||||
if guid:
|
||||
return guid
|
||||
return link
|
||||
|
||||
|
||||
def clean_snippet(s: str) -> str:
|
||||
s = re.sub(r"<[^>]+>", " ", s or "")
|
||||
s = re.sub(r"\s+", " ", s)
|
||||
return s.strip()
|
||||
|
||||
|
||||
def _struct_time_to_iso(st: Any) -> str | None:
|
||||
if not st:
|
||||
return None
|
||||
try:
|
||||
return datetime.datetime(*st[:6], tzinfo=datetime.timezone.utc).isoformat()
|
||||
except (TypeError, ValueError):
|
||||
return None
|
||||
|
||||
|
||||
def parse_feed_body(src: Source, body: bytes) -> list[dict[str, Any]]:
|
||||
parsed = feedparser.parse(body)
|
||||
items: list[dict[str, Any]] = []
|
||||
for entry in parsed.entries[:MAX_ITEMS_PER_FEED]:
|
||||
link = (entry.get("link") or "").strip()
|
||||
guid = (entry.get("id") or entry.get("guid") or "").strip()
|
||||
title = (entry.get("title") or "").strip()
|
||||
summary = entry.get("summary") or ""
|
||||
published_at = (
|
||||
_struct_time_to_iso(entry.get("published_parsed"))
|
||||
or _struct_time_to_iso(entry.get("updated_parsed"))
|
||||
)
|
||||
blob = f"{title}\n{summary}"
|
||||
cves = extract_cves(blob)
|
||||
vendor_ids = extract_vendor_ids(blob, src.advisory_id_patterns)
|
||||
stable_id = pick_stable_id(vendor_ids, cves, guid, link)
|
||||
items.append({
|
||||
"source": src.name,
|
||||
"stable_id": stable_id,
|
||||
"title": title,
|
||||
"permalink": link,
|
||||
"guid": guid,
|
||||
"published_at": published_at,
|
||||
"extracted_cves": cves,
|
||||
"vendor_ids": vendor_ids,
|
||||
"snippet": clean_snippet(summary)[:SNIPPET_MAX],
|
||||
})
|
||||
return items
|
||||
|
||||
|
||||
def _parse_intel_psirt(src: Source, text: str) -> list[dict[str, Any]]:
|
||||
"""Intel's security-center page uses a table of <tr class="data"> rows:
|
||||
|
||||
<tr class="data" ...>
|
||||
<td ...><a href="/.../intel-sa-NNNNN.html">Title</a></td>
|
||||
<td>INTEL-SA-NNNNN</td>
|
||||
<td>March 10, 2026</td> <- Last updated
|
||||
<td>March 10, 2026</td> <- First published
|
||||
</tr>
|
||||
|
||||
We pick the later of the two dates as `published_at` (most recent
|
||||
activity) so updates to older advisories also show up in the window.
|
||||
"""
|
||||
items: list[dict[str, Any]] = []
|
||||
seen_ids: set[str] = set()
|
||||
permalink_base = src.display_url or src.url
|
||||
for m in re.finditer(r'<tr class="data"[^>]*>(.*?)</tr>', text, re.DOTALL):
|
||||
row = m.group(1)
|
||||
sid = re.search(r'INTEL-SA-\d+', row)
|
||||
if not sid:
|
||||
continue
|
||||
advisory_id = sid.group(0)
|
||||
if advisory_id in seen_ids:
|
||||
continue
|
||||
seen_ids.add(advisory_id)
|
||||
link_m = re.search(r'href="([^"#]+)"', row)
|
||||
permalink = urllib.parse.urljoin(permalink_base, link_m.group(1)) if link_m else permalink_base
|
||||
title_m = re.search(r'<a[^>]*>([^<]+)</a>', row)
|
||||
title = title_m.group(1).strip() if title_m else advisory_id
|
||||
published_at: str | None = None
|
||||
for ds in re.findall(r'<td[^>]*>\s*([A-Z][a-z]+ \d{1,2}, \d{4})\s*</td>', row):
|
||||
try:
|
||||
dt = datetime.datetime.strptime(ds, "%B %d, %Y").replace(tzinfo=datetime.timezone.utc)
|
||||
iso = dt.isoformat()
|
||||
if published_at is None or iso > published_at:
|
||||
published_at = iso
|
||||
except ValueError:
|
||||
continue
|
||||
items.append({
|
||||
"source": src.name,
|
||||
"stable_id": advisory_id,
|
||||
"title": title,
|
||||
"permalink": permalink,
|
||||
"guid": "",
|
||||
"published_at": published_at,
|
||||
"extracted_cves": extract_cves(row),
|
||||
"vendor_ids": [advisory_id],
|
||||
"snippet": clean_snippet(row)[:SNIPPET_MAX],
|
||||
})
|
||||
return items[:MAX_ITEMS_PER_FEED]
|
||||
|
||||
|
||||
def _parse_amd_psirt(src: Source, text: str) -> list[dict[str, Any]]:
|
||||
"""AMD's product-security page has a bulletin table where each row ends
|
||||
with two `<td data-sort="YYYY-MM-DD HHMMSS">` cells (Published Date,
|
||||
Last Updated Date). The machine-readable `data-sort` attribute is far
|
||||
easier to parse than the human-readable text alongside it.
|
||||
"""
|
||||
items: list[dict[str, Any]] = []
|
||||
seen_ids: set[str] = set()
|
||||
permalink_base = src.display_url or src.url
|
||||
for m in re.finditer(r'<tr[^>]*>(.*?AMD-SB-\d+.*?)</tr>', text, re.DOTALL):
|
||||
row = m.group(1)
|
||||
sid = re.search(r'AMD-SB-\d+', row)
|
||||
if not sid:
|
||||
continue
|
||||
advisory_id = sid.group(0)
|
||||
if advisory_id in seen_ids:
|
||||
continue
|
||||
seen_ids.add(advisory_id)
|
||||
link_m = re.search(r'href="([^"#]+)"', row)
|
||||
permalink = urllib.parse.urljoin(permalink_base, link_m.group(1)) if link_m else permalink_base
|
||||
title_m = re.search(r'<a[^>]*>([^<]+)</a>', row)
|
||||
title = title_m.group(1).strip() if title_m else advisory_id
|
||||
published_at: str | None = None
|
||||
for (y, mo, d, h, mi, s) in re.findall(
|
||||
r'data-sort="(\d{4})-(\d{2})-(\d{2})\s+(\d{2})(\d{2})(\d{2})"', row
|
||||
):
|
||||
iso = f"{y}-{mo}-{d}T{h}:{mi}:{s}+00:00"
|
||||
if published_at is None or iso > published_at:
|
||||
published_at = iso
|
||||
items.append({
|
||||
"source": src.name,
|
||||
"stable_id": advisory_id,
|
||||
"title": title,
|
||||
"permalink": permalink,
|
||||
"guid": "",
|
||||
"published_at": published_at,
|
||||
"extracted_cves": extract_cves(row),
|
||||
"vendor_ids": [advisory_id],
|
||||
"snippet": clean_snippet(row)[:SNIPPET_MAX],
|
||||
})
|
||||
return items[:MAX_ITEMS_PER_FEED]
|
||||
|
||||
|
||||
def _parse_html_generic(src: Source, text: str) -> list[dict[str, Any]]:
|
||||
"""Fallback regex-only extractor for HTML sources with no known table
|
||||
layout (arm-spec, transient-fail's tree.js). Emits `published_at=None`
|
||||
— items pass the window filter as fail-safe, but state.seen dedup
|
||||
prevents re-emission across runs."""
|
||||
items: list[dict[str, Any]] = []
|
||||
seen_ids: set[str] = set()
|
||||
permalink_base = src.display_url or src.url
|
||||
for pat in src.advisory_id_patterns:
|
||||
for m in re.finditer(pat, text):
|
||||
advisory_id = m.group(0)
|
||||
if advisory_id in seen_ids:
|
||||
continue
|
||||
seen_ids.add(advisory_id)
|
||||
window = text[max(0, m.start() - 400): m.end() + 400]
|
||||
href_match = re.search(r'href="([^"#]+)"', window)
|
||||
if href_match:
|
||||
permalink = urllib.parse.urljoin(permalink_base, href_match.group(1))
|
||||
else:
|
||||
permalink = permalink_base
|
||||
cves_in_window = extract_cves(window)
|
||||
is_cve = advisory_id.startswith("CVE-")
|
||||
cves = cves_in_window if not is_cve else list({advisory_id, *cves_in_window})
|
||||
vendor_ids = [] if is_cve else [advisory_id]
|
||||
items.append({
|
||||
"source": src.name,
|
||||
"stable_id": advisory_id,
|
||||
"title": advisory_id,
|
||||
"permalink": permalink,
|
||||
"guid": "",
|
||||
"published_at": None,
|
||||
"extracted_cves": cves,
|
||||
"vendor_ids": vendor_ids,
|
||||
"snippet": clean_snippet(window)[:SNIPPET_MAX],
|
||||
})
|
||||
return items[:MAX_ITEMS_PER_FEED]
|
||||
|
||||
|
||||
_HTML_PARSERS = {
|
||||
"intel-psirt": _parse_intel_psirt,
|
||||
"amd-psirt": _parse_amd_psirt,
|
||||
}
|
||||
|
||||
|
||||
def parse_html_body(src: Source, body: bytes) -> list[dict[str, Any]]:
|
||||
"""Dispatch to a per-source HTML parser when one is registered;
|
||||
fall back to the generic regex-over-advisory-IDs extractor."""
|
||||
text = body.decode("utf-8", errors="replace")
|
||||
parser = _HTML_PARSERS.get(src.name, _parse_html_generic)
|
||||
return parser(src, text)
|
||||
|
||||
|
||||
def parse_body(src: Source, body: bytes) -> list[dict[str, Any]]:
|
||||
return parse_feed_body(src, body) if src.kind in ("rss", "atom") else parse_html_body(src, body)
|
||||
|
||||
|
||||
def compute_cutoff(
|
||||
scan_now: datetime.datetime,
|
||||
last_run: str | None,
|
||||
window_hours: float = DEFAULT_WINDOW_HOURS,
|
||||
) -> datetime.datetime:
|
||||
base = scan_now - datetime.timedelta(hours=window_hours)
|
||||
lr = parse_iso(last_run)
|
||||
if lr is None:
|
||||
return base
|
||||
widened = scan_now - (scan_now - lr + datetime.timedelta(hours=1))
|
||||
return min(base, widened)
|
||||
|
||||
|
||||
def _resolve_window_hours() -> float:
|
||||
"""Pick up WINDOW_HOURS from the environment (set by workflow_dispatch).
|
||||
Falls back to DEFAULT_WINDOW_HOURS for cron runs or local invocations."""
|
||||
raw = os.environ.get("WINDOW_HOURS", "").strip()
|
||||
if not raw:
|
||||
return float(DEFAULT_WINDOW_HOURS)
|
||||
try:
|
||||
v = float(raw)
|
||||
if v <= 0:
|
||||
raise ValueError("must be > 0")
|
||||
return v
|
||||
except ValueError:
|
||||
print(f"warning: ignoring invalid WINDOW_HOURS={raw!r}, using {DEFAULT_WINDOW_HOURS}",
|
||||
file=sys.stderr)
|
||||
return float(DEFAULT_WINDOW_HOURS)
|
||||
|
||||
|
||||
def _resolve_reconsider_age_days() -> float:
|
||||
"""Pick up RECONSIDER_AGE_DAYS from the environment. Entries whose last
|
||||
review (reconsidered_at, or first_seen if never reconsidered) is more
|
||||
recent than this many days ago are skipped. 0 = reconsider everything
|
||||
every run (no throttle)."""
|
||||
raw = os.environ.get("RECONSIDER_AGE_DAYS", "").strip()
|
||||
if not raw:
|
||||
return float(DEFAULT_RECONSIDER_AGE_DAYS)
|
||||
try:
|
||||
v = float(raw)
|
||||
if v < 0:
|
||||
raise ValueError("must be >= 0")
|
||||
return v
|
||||
except ValueError:
|
||||
print(f"warning: ignoring invalid RECONSIDER_AGE_DAYS={raw!r}, "
|
||||
f"using {DEFAULT_RECONSIDER_AGE_DAYS}", file=sys.stderr)
|
||||
return float(DEFAULT_RECONSIDER_AGE_DAYS)
|
||||
|
||||
|
||||
def backlog_to_reconsider(
|
||||
data: dict[str, Any],
|
||||
scan_now: datetime.datetime,
|
||||
min_age_days: float = DEFAULT_RECONSIDER_AGE_DAYS,
|
||||
) -> list[dict[str, Any]]:
|
||||
"""Walk state.seen and emit toimplement/tocheck entries for re-review.
|
||||
|
||||
Throttle: skip entries whose "last review" timestamp is more recent
|
||||
than `min_age_days` ago. "Last review" is `reconsidered_at` if Claude
|
||||
has already reconsidered the entry at least once, otherwise
|
||||
`first_seen` (the initial classification was itself a review). With
|
||||
`min_age_days=0` the throttle is disabled — every qualifying entry
|
||||
is emitted on every run.
|
||||
|
||||
Items in `unrelated` are never emitted — those are settled.
|
||||
A CVE alias pointing at this canonical is included in `extracted_cves`
|
||||
so Claude sees every known CVE for the item without having to consult
|
||||
the full alias map.
|
||||
"""
|
||||
seen = data.get("seen", {})
|
||||
aliases = data.get("aliases", {})
|
||||
by_canonical: dict[str, list[str]] = {}
|
||||
for alt, canon in aliases.items():
|
||||
by_canonical.setdefault(canon, []).append(alt)
|
||||
|
||||
# Any entry whose last review is newer than this ISO cutoff is throttled.
|
||||
cutoff = (scan_now - datetime.timedelta(days=min_age_days)).isoformat()
|
||||
|
||||
out: list[dict[str, Any]] = []
|
||||
for canonical, rec in seen.items():
|
||||
if rec.get("bucket") not in ("toimplement", "tocheck"):
|
||||
continue
|
||||
last_reviewed = rec.get("reconsidered_at") or rec.get("first_seen") or ""
|
||||
if min_age_days > 0 and last_reviewed and last_reviewed > cutoff:
|
||||
continue
|
||||
cves: list[str] = []
|
||||
if canonical.startswith("CVE-"):
|
||||
cves.append(canonical)
|
||||
for alt in by_canonical.get(canonical, []):
|
||||
if alt.startswith("CVE-") and alt not in cves:
|
||||
cves.append(alt)
|
||||
out.append({
|
||||
"canonical_id": canonical,
|
||||
"current_bucket": rec.get("bucket"),
|
||||
"title": rec.get("title") or "",
|
||||
"sources": list(rec.get("sources") or []),
|
||||
"urls": list(rec.get("urls") or []),
|
||||
"extracted_cves": cves,
|
||||
"first_seen": rec.get("first_seen"),
|
||||
"reconsidered_at": rec.get("reconsidered_at"),
|
||||
})
|
||||
return out
|
||||
|
||||
|
||||
def candidate_ids(item: dict[str, Any]) -> list[str]:
|
||||
"""All identifiers under which this item might already be known."""
|
||||
seen: set[str] = set()
|
||||
out: list[str] = []
|
||||
for cand in (
|
||||
*(item.get("extracted_cves") or []),
|
||||
*(item.get("vendor_ids") or []),
|
||||
item.get("stable_id"),
|
||||
item.get("guid"),
|
||||
item.get("permalink"),
|
||||
):
|
||||
if cand and cand not in seen:
|
||||
seen.add(cand)
|
||||
out.append(cand)
|
||||
return out
|
||||
|
||||
|
||||
def main() -> int:
|
||||
ap = argparse.ArgumentParser()
|
||||
ap.add_argument("--scan-date", default=os.environ.get("SCAN_DATE", ""))
|
||||
ap.add_argument("--output", type=pathlib.Path, default=NEW_ITEMS_PATH)
|
||||
args = ap.parse_args()
|
||||
|
||||
scan_now = now_from_scan_date(args.scan_date)
|
||||
scan_date_iso = scan_now.isoformat()
|
||||
window_hours = _resolve_window_hours()
|
||||
reconsider_age_days = _resolve_reconsider_age_days()
|
||||
data = state.load()
|
||||
cutoff = compute_cutoff(scan_now, data.get("last_run"), window_hours)
|
||||
|
||||
per_source: dict[str, dict[str, Any]] = {}
|
||||
all_new: list[dict[str, Any]] = []
|
||||
|
||||
for src in SOURCES:
|
||||
meta = dict(data["sources"].get(src.name, {}))
|
||||
status, body, etag, last_modified = conditional_get(
|
||||
src.url, meta.get("etag"), meta.get("last_modified"),
|
||||
user_agent=src.user_agent or USER_AGENT,
|
||||
)
|
||||
meta["last_fetched_at"] = scan_date_iso
|
||||
meta["last_status"] = status
|
||||
|
||||
if isinstance(status, str) or (isinstance(status, int) and status >= 400 and status != 304):
|
||||
per_source[src.name] = {"status": status, "new": 0}
|
||||
data["sources"][src.name] = meta
|
||||
continue
|
||||
|
||||
if status == 304 or body is None:
|
||||
per_source[src.name] = {"status": 304, "new": 0}
|
||||
data["sources"][src.name] = meta
|
||||
continue
|
||||
|
||||
# Refresh cache headers only on successful 200.
|
||||
if etag:
|
||||
meta["etag"] = etag
|
||||
if last_modified:
|
||||
meta["last_modified"] = last_modified
|
||||
|
||||
items = parse_body(src, body)
|
||||
total = len(items)
|
||||
|
||||
in_window = []
|
||||
for it in items:
|
||||
pub = parse_iso(it.get("published_at"))
|
||||
if pub is None or pub >= cutoff:
|
||||
in_window.append(it)
|
||||
|
||||
new: list[dict[str, Any]] = []
|
||||
hwm_pub = meta.get("hwm_published_at")
|
||||
hwm_id = meta.get("hwm_id")
|
||||
for it in in_window:
|
||||
if state.lookup(data, candidate_ids(it)) is not None:
|
||||
continue
|
||||
new.append(it)
|
||||
pub = it.get("published_at")
|
||||
if pub and (not hwm_pub or pub > hwm_pub):
|
||||
hwm_pub = pub
|
||||
hwm_id = it.get("stable_id")
|
||||
|
||||
if new:
|
||||
meta["hwm_published_at"] = hwm_pub
|
||||
meta["hwm_id"] = hwm_id
|
||||
|
||||
data["sources"][src.name] = meta
|
||||
per_source[src.name] = {"status": status, "new": len(new), "total_in_feed": total}
|
||||
all_new.extend(new)
|
||||
|
||||
# Persist updated HTTP cache metadata regardless of whether Claude runs.
|
||||
state.save(data)
|
||||
|
||||
reconsider = backlog_to_reconsider(data, scan_now, reconsider_age_days)
|
||||
|
||||
out = {
|
||||
"scan_date": scan_date_iso,
|
||||
"window_cutoff": cutoff.isoformat(),
|
||||
"per_source": per_source,
|
||||
"items": all_new,
|
||||
"reconsider": reconsider,
|
||||
}
|
||||
args.output.write_text(json.dumps(out, indent=2, sort_keys=True) + "\n")
|
||||
|
||||
# GitHub Actions step outputs. Downstream `if:` conditions gate the
|
||||
# classify step on `new_count || reconsider_count`; both must be 0
|
||||
# for Claude to be skipped.
|
||||
gh_out = os.environ.get("GITHUB_OUTPUT")
|
||||
if gh_out:
|
||||
with open(gh_out, "a") as f:
|
||||
f.write(f"new_count={len(all_new)}\n")
|
||||
f.write(f"reconsider_count={len(reconsider)}\n")
|
||||
failures = [
|
||||
s for s, v in per_source.items()
|
||||
if not (isinstance(v["status"], int) and v["status"] in (200, 304))
|
||||
]
|
||||
f.write(f"fetch_failures_count={len(failures)}\n")
|
||||
|
||||
print(f"Scan date: {scan_date_iso}")
|
||||
print(f"Window: {window_hours:g} h")
|
||||
print(f"Cutoff: {cutoff.isoformat()}")
|
||||
print(f"New items: {len(all_new)}")
|
||||
if reconsider_age_days == 0:
|
||||
print(f"Reconsider: {len(reconsider)} (throttle disabled)")
|
||||
else:
|
||||
print(f"Reconsider: {len(reconsider)} (throttle: "
|
||||
f"skip entries reviewed <{reconsider_age_days:g}d ago)")
|
||||
for s, v in per_source.items():
|
||||
print(f" {s:14s} status={str(v['status']):>16} new={v['new']}")
|
||||
|
||||
return 0
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
sys.exit(main())
|
||||
@@ -0,0 +1,298 @@
|
||||
#!/usr/bin/env python3
|
||||
"""Merge Claude's classifications.json into state/seen.json.
|
||||
|
||||
Inputs:
|
||||
state/seen.json (already has updated .sources from fetch_and_diff)
|
||||
classifications.json (written by the Claude step; list of records)
|
||||
new_items.json (fallback source of per-item metadata, if Claude
|
||||
omitted urls/sources in a record)
|
||||
|
||||
Each classification record has shape:
|
||||
{
|
||||
"stable_id": "...", # required (the key used in new_items.json)
|
||||
"canonical_id": "...", # optional; defaults to first extracted_cves, else stable_id
|
||||
"bucket": "toimplement|tocheck|unrelated",
|
||||
"extracted_cves": ["...", ...], # optional
|
||||
"sources": ["...", ...], # optional
|
||||
"urls": ["...", ...], # optional
|
||||
"reconsider": true # optional; set by Claude for reconsidered
|
||||
# backlog entries — merge overwrites
|
||||
# the stored bucket (incl. demotions)
|
||||
# instead of promoting
|
||||
}
|
||||
|
||||
Behavior:
|
||||
- For records WITHOUT `reconsider: true` (fresh items):
|
||||
upsert seen[canonical_id], union sources/urls, promote bucket strength.
|
||||
- For records WITH `reconsider: true` (previously-classified entries):
|
||||
overwrite the stored bucket unconditionally (permits demotions), union
|
||||
sources/urls. If Claude's canonical_id differs from the stable_id (the
|
||||
previous canonical), rekey the seen entry under the new ID and leave
|
||||
the old as an alias — used when a CVE has since been assigned to what
|
||||
was previously a bare vendor-ID entry.
|
||||
- For every alt_id in (stable_id, vendor_ids, extracted_cves) that differs
|
||||
from canonical_id, set aliases[alt_id] = canonical_id.
|
||||
- Update last_run to SCAN_DATE.
|
||||
- Prune entries older than RETENTION_DAYS (180) before writing.
|
||||
- Also writes the three daily watch_*.md files as stubs if Claude didn't run
|
||||
(i.e. when new_items.json was empty and the classify step was skipped).
|
||||
"""
|
||||
from __future__ import annotations
|
||||
|
||||
import argparse
|
||||
import datetime
|
||||
import json
|
||||
import os
|
||||
import pathlib
|
||||
import sys
|
||||
from typing import Any
|
||||
|
||||
from . import state
|
||||
|
||||
|
||||
RETENTION_DAYS = 180
|
||||
NEW_ITEMS_PATH = pathlib.Path("new_items.json")
|
||||
CLASSIFICATIONS_PATH = pathlib.Path("classifications.json")
|
||||
|
||||
|
||||
def _load_json(path: pathlib.Path, default: Any) -> Any:
|
||||
if not path.exists():
|
||||
return default
|
||||
return json.loads(path.read_text())
|
||||
|
||||
|
||||
def _canonical(record: dict[str, Any], fallback_meta: dict[str, Any] | None) -> str:
|
||||
if record.get("canonical_id"):
|
||||
return record["canonical_id"]
|
||||
cves = record.get("extracted_cves") or (fallback_meta or {}).get("extracted_cves") or []
|
||||
if cves:
|
||||
return cves[0]
|
||||
return record["stable_id"]
|
||||
|
||||
|
||||
def _alt_ids(record: dict[str, Any], fallback_meta: dict[str, Any] | None) -> list[str]:
|
||||
ids: list[str] = []
|
||||
ids.append(record.get("stable_id", ""))
|
||||
ids.extend(record.get("extracted_cves") or [])
|
||||
if fallback_meta:
|
||||
ids.extend(fallback_meta.get("extracted_cves") or [])
|
||||
ids.extend(fallback_meta.get("vendor_ids") or [])
|
||||
guid = fallback_meta.get("guid")
|
||||
if guid:
|
||||
ids.append(guid)
|
||||
link = fallback_meta.get("permalink")
|
||||
if link:
|
||||
ids.append(link)
|
||||
return [i for i in ids if i]
|
||||
|
||||
|
||||
def _unique(seq: list[str]) -> list[str]:
|
||||
seen: set[str] = set()
|
||||
out: list[str] = []
|
||||
for x in seq:
|
||||
if x and x not in seen:
|
||||
seen.add(x)
|
||||
out.append(x)
|
||||
return out
|
||||
|
||||
|
||||
def merge(
|
||||
data: dict[str, Any],
|
||||
classifications: list[dict[str, Any]],
|
||||
new_items_by_stable_id: dict[str, dict[str, Any]],
|
||||
scan_date: str,
|
||||
) -> None:
|
||||
for rec in classifications:
|
||||
if not rec.get("stable_id"):
|
||||
continue
|
||||
if rec.get("reconsider"):
|
||||
_apply_reconsider(data, rec, scan_date)
|
||||
else:
|
||||
_apply_new_item(data, rec, new_items_by_stable_id, scan_date)
|
||||
|
||||
|
||||
def _apply_new_item(
|
||||
data: dict[str, Any],
|
||||
rec: dict[str, Any],
|
||||
new_items_by_stable_id: dict[str, dict[str, Any]],
|
||||
scan_date: str,
|
||||
) -> None:
|
||||
stable_id = rec["stable_id"]
|
||||
meta = new_items_by_stable_id.get(stable_id, {})
|
||||
canonical = _canonical(rec, meta)
|
||||
bucket = rec.get("bucket", "unrelated")
|
||||
title = (meta.get("title") or "").strip()
|
||||
|
||||
existing = data["seen"].get(canonical)
|
||||
if existing is None:
|
||||
data["seen"][canonical] = {
|
||||
"bucket": bucket,
|
||||
"first_seen": scan_date,
|
||||
"seen_at": scan_date,
|
||||
"title": title,
|
||||
"sources": _unique(list(rec.get("sources") or []) + ([meta.get("source")] if meta.get("source") else [])),
|
||||
"urls": _unique(list(rec.get("urls") or []) + ([meta.get("permalink")] if meta.get("permalink") else [])),
|
||||
}
|
||||
else:
|
||||
existing["bucket"] = state.promote_bucket(existing["bucket"], bucket)
|
||||
existing["seen_at"] = scan_date
|
||||
existing.setdefault("first_seen", existing.get("seen_at") or scan_date)
|
||||
if not existing.get("title") and title:
|
||||
existing["title"] = title
|
||||
existing["sources"] = _unique(list(existing.get("sources") or []) + list(rec.get("sources") or []) + ([meta.get("source")] if meta.get("source") else []))
|
||||
existing["urls"] = _unique(list(existing.get("urls") or []) + list(rec.get("urls") or []) + ([meta.get("permalink")] if meta.get("permalink") else []))
|
||||
|
||||
for alt in _alt_ids(rec, meta):
|
||||
if alt != canonical:
|
||||
data["aliases"][alt] = canonical
|
||||
|
||||
|
||||
def _apply_reconsider(
|
||||
data: dict[str, Any],
|
||||
rec: dict[str, Any],
|
||||
scan_date: str,
|
||||
) -> None:
|
||||
"""Re-review of a previously-classified entry. The record's stable_id
|
||||
is the entry's current canonical key in state; `canonical_id` may name
|
||||
a new key (e.g. a freshly-assigned CVE) — in which case we rekey."""
|
||||
old_key = rec["stable_id"]
|
||||
new_canonical = _canonical(rec, None)
|
||||
bucket = rec.get("bucket", "unrelated")
|
||||
|
||||
# Resolve the current record — may need to follow an alias if the
|
||||
# backlog snapshot the classifier reviewed is slightly out of sync.
|
||||
current_key = old_key if old_key in data["seen"] else data["aliases"].get(old_key)
|
||||
if not current_key or current_key not in data["seen"]:
|
||||
print(f"warning: reconsider record for {old_key!r} points at no "
|
||||
f"state entry; skipping.", file=sys.stderr)
|
||||
return
|
||||
|
||||
existing = data["seen"][current_key]
|
||||
|
||||
# Overwrite bucket unconditionally (allows demotions) and stamp the
|
||||
# reconsideration date so we can later throttle if this grows.
|
||||
existing["bucket"] = bucket
|
||||
existing["seen_at"] = scan_date
|
||||
existing["reconsidered_at"] = scan_date
|
||||
|
||||
# Union any fresh sources/urls the classifier surfaced.
|
||||
if rec.get("sources"):
|
||||
existing["sources"] = _unique(list(existing.get("sources") or []) + list(rec["sources"]))
|
||||
if rec.get("urls"):
|
||||
existing["urls"] = _unique(list(existing.get("urls") or []) + list(rec["urls"]))
|
||||
|
||||
# Alias every alt ID the classifier provided to the current key
|
||||
# (before a possible rekey below redirects them).
|
||||
for alt in _alt_ids(rec, None):
|
||||
if alt != current_key:
|
||||
data["aliases"][alt] = current_key
|
||||
|
||||
# Rekey if Claude newly identified a canonical ID (e.g., a CVE for a
|
||||
# vendor-ID entry). If the destination already exists, merge; else
|
||||
# move. In both cases, retarget all aliases and leave the old key
|
||||
# itself as an alias.
|
||||
if new_canonical and new_canonical != current_key:
|
||||
if new_canonical in data["seen"]:
|
||||
dest = data["seen"][new_canonical]
|
||||
dest["bucket"] = state.promote_bucket(dest.get("bucket", "unrelated"), existing.get("bucket", "unrelated"))
|
||||
dest["sources"] = _unique(list(dest.get("sources") or []) + list(existing.get("sources") or []))
|
||||
dest["urls"] = _unique(list(dest.get("urls") or []) + list(existing.get("urls") or []))
|
||||
if not dest.get("title") and existing.get("title"):
|
||||
dest["title"] = existing["title"]
|
||||
dest["seen_at"] = scan_date
|
||||
dest["reconsidered_at"] = scan_date
|
||||
dest.setdefault("first_seen", existing.get("first_seen") or scan_date)
|
||||
del data["seen"][current_key]
|
||||
else:
|
||||
data["seen"][new_canonical] = existing
|
||||
del data["seen"][current_key]
|
||||
|
||||
for alias_key, target in list(data["aliases"].items()):
|
||||
if target == current_key:
|
||||
data["aliases"][alias_key] = new_canonical
|
||||
data["aliases"][current_key] = new_canonical
|
||||
# Clean up any self-aliases the retarget may have produced.
|
||||
for k in [k for k, v in data["aliases"].items() if k == v]:
|
||||
del data["aliases"][k]
|
||||
|
||||
|
||||
def ensure_stub_reports(scan_date: str) -> None:
|
||||
"""If the Claude step was skipped, write empty stub watch_*.md files so the
|
||||
report artifact is consistent across runs."""
|
||||
day = scan_date[:10] # YYYY-MM-DD
|
||||
stub = "(no new items in this window)\n"
|
||||
for bucket in ("toimplement", "tocheck", "unrelated"):
|
||||
p = pathlib.Path(f"watch_{day}_{bucket}.md")
|
||||
if not p.exists():
|
||||
p.write_text(stub)
|
||||
|
||||
|
||||
def write_snapshots(data: dict[str, Any], scan_date: str) -> None:
|
||||
"""Write current_toimplement.md and current_tocheck.md — full backlog
|
||||
snapshots reflecting every entry in state under those buckets. A human
|
||||
who reads only the latest run's artifact sees the complete picture
|
||||
without having to consult prior runs."""
|
||||
for bucket in ("toimplement", "tocheck"):
|
||||
entries = [
|
||||
(cid, rec) for cid, rec in data["seen"].items()
|
||||
if rec.get("bucket") == bucket
|
||||
]
|
||||
# Oldest first — long-lingering items stay at the top as a reminder.
|
||||
entries.sort(key=lambda kv: kv[1].get("first_seen") or kv[1].get("seen_at") or "")
|
||||
out = [
|
||||
f"# Current `{bucket}` backlog",
|
||||
"",
|
||||
f"_Snapshot as of {scan_date}. "
|
||||
f"{len(entries)} item(s). Oldest first._",
|
||||
"",
|
||||
]
|
||||
if not entries:
|
||||
out.append("(backlog is empty)")
|
||||
else:
|
||||
for cid, rec in entries:
|
||||
title = rec.get("title") or ""
|
||||
first_seen = (rec.get("first_seen") or rec.get("seen_at") or "")[:10]
|
||||
sources = ", ".join(rec.get("sources") or []) or "(none)"
|
||||
out.append(f"- **{cid}**" + (f" — {title}" if title else ""))
|
||||
out.append(f" first seen {first_seen} · sources: {sources}")
|
||||
for u in rec.get("urls") or []:
|
||||
out.append(f" - {u}")
|
||||
out.append("")
|
||||
pathlib.Path(f"current_{bucket}.md").write_text("\n".join(out))
|
||||
|
||||
|
||||
def main() -> int:
|
||||
ap = argparse.ArgumentParser()
|
||||
ap.add_argument("--scan-date", default=os.environ.get("SCAN_DATE", ""))
|
||||
ap.add_argument("--classifications", type=pathlib.Path, default=CLASSIFICATIONS_PATH)
|
||||
ap.add_argument("--new-items", type=pathlib.Path, default=NEW_ITEMS_PATH)
|
||||
args = ap.parse_args()
|
||||
|
||||
scan_date = args.scan_date or datetime.datetime.now(datetime.timezone.utc).isoformat()
|
||||
|
||||
data = state.load()
|
||||
classifications = _load_json(args.classifications, [])
|
||||
new_items_doc = _load_json(args.new_items, {"items": []})
|
||||
new_items_by_stable_id = {it["stable_id"]: it for it in new_items_doc.get("items", []) if it.get("stable_id")}
|
||||
|
||||
if not isinstance(classifications, list):
|
||||
print(f"warning: {args.classifications} is not a list; ignoring", file=sys.stderr)
|
||||
classifications = []
|
||||
|
||||
merge(data, classifications, new_items_by_stable_id, scan_date)
|
||||
data["last_run"] = scan_date
|
||||
|
||||
scan_now = datetime.datetime.fromisoformat(scan_date.replace("Z", "+00:00"))
|
||||
before, after = state.prune(data, RETENTION_DAYS, scan_now)
|
||||
state.save(data)
|
||||
ensure_stub_reports(scan_date)
|
||||
write_snapshots(data, scan_date)
|
||||
|
||||
print(f"Merged {len(classifications)} classifications.")
|
||||
print(f"Pruned seen: {before} -> {after} entries (retention={RETENTION_DAYS}d).")
|
||||
print(f"Aliases: {len(data['aliases'])}.")
|
||||
return 0
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
sys.exit(main())
|
||||
@@ -0,0 +1,59 @@
|
||||
"""Declarative list of sources polled by the daily vuln scan."""
|
||||
from dataclasses import dataclass
|
||||
from typing import Literal
|
||||
|
||||
Kind = Literal["rss", "atom", "html"]
|
||||
|
||||
|
||||
@dataclass(frozen=True)
|
||||
class Source:
|
||||
name: str
|
||||
url: str
|
||||
kind: Kind
|
||||
# For HTML sources: regexes used to extract advisory IDs from the page.
|
||||
advisory_id_patterns: tuple[str, ...] = ()
|
||||
# Human-facing URL to use as permalink fallback when `url` points at a
|
||||
# non-browsable endpoint (e.g. a JS data file). Empty = use `url`.
|
||||
display_url: str = ""
|
||||
# Per-source UA override. AMD's CDN drops connections when the UA string
|
||||
# contains a parenthesized URL, while Intel/ARM's WAF rejects UAs that
|
||||
# don't identify themselves — so we can't use one UA everywhere.
|
||||
# Empty = use the module-level USER_AGENT.
|
||||
user_agent: str = ""
|
||||
|
||||
|
||||
SOURCES: tuple[Source, ...] = (
|
||||
Source("phoronix", "https://www.phoronix.com/rss.php", "rss"),
|
||||
Source("oss-sec", "https://seclists.org/rss/oss-sec.rss", "rss"),
|
||||
Source("lwn", "https://lwn.net/headlines/newrss", "rss"),
|
||||
Source("project-zero", "https://googleprojectzero.blogspot.com/feeds/posts/default", "atom"),
|
||||
Source("vusec", "https://www.vusec.net/feed/", "rss"),
|
||||
Source("comsec-eth", "https://comsec.ethz.ch/category/news/feed/", "rss"),
|
||||
# api.msrc.microsoft.com/update-guide/rss is the real RSS endpoint; the
|
||||
# msrc.microsoft.com/... URL returns the SPA shell (2.7 KB) instead.
|
||||
Source("msrc", "https://api.msrc.microsoft.com/update-guide/rss", "rss"),
|
||||
Source("cisa", "https://www.cisa.gov/cybersecurity-advisories/all.xml", "rss"),
|
||||
Source("cert-cc", "https://www.kb.cert.org/vuls/atomfeed/", "atom"),
|
||||
Source("intel-psirt", "https://www.intel.com/content/www/us/en/security-center/default.html", "html",
|
||||
(r"INTEL-SA-\d+",)),
|
||||
Source("amd-psirt", "https://www.amd.com/en/resources/product-security.html", "html",
|
||||
(r"AMD-SB-\d+",),
|
||||
user_agent="spectre-meltdown-checker/vuln-watch"),
|
||||
Source("arm-spec", "https://developer.arm.com/Arm%20Security%20Center/Speculative%20Processor%20Vulnerability", "html",
|
||||
(r"CVE-\d{4}-\d{4,7}",)),
|
||||
# transient.fail renders its attack table from tree.js client-side; we
|
||||
# pull the JS file directly (CVE regex works on its JSON-ish body).
|
||||
Source("transient-fail", "https://transient.fail/tree.js", "html",
|
||||
(r"CVE-\d{4}-\d{4,7}",),
|
||||
display_url="https://transient.fail/"),
|
||||
)
|
||||
|
||||
# Identify ourselves honestly. Akamai/Cloudflare WAFs fronting intel.com,
|
||||
# developer.arm.com, and cisa.gov return 403 when the UA claims "Mozilla"
|
||||
# but TLS/HTTP fingerprint doesn't match a real browser — an honest bot UA
|
||||
# passes those rules cleanly.
|
||||
USER_AGENT = (
|
||||
"spectre-meltdown-checker/vuln-watch "
|
||||
"(+https://github.com/speed47/spectre-meltdown-checker)"
|
||||
)
|
||||
REQUEST_TIMEOUT = 30
|
||||
@@ -0,0 +1,137 @@
|
||||
"""Load/save/migrate/lookup helpers for state/seen.json.
|
||||
|
||||
Schema v2:
|
||||
{
|
||||
"schema_version": 2,
|
||||
"last_run": "<iso8601>|null",
|
||||
"sources": {
|
||||
"<name>": {
|
||||
"etag": "...",
|
||||
"last_modified": "...",
|
||||
"hwm_id": "...",
|
||||
"hwm_published_at": "<iso8601>",
|
||||
"last_fetched_at": "<iso8601>",
|
||||
"last_status": 200|304|<http-err>|"<str-err>"
|
||||
}
|
||||
},
|
||||
"seen": {
|
||||
"<canonical_id>": {
|
||||
"bucket": "toimplement|tocheck|unrelated",
|
||||
"seen_at": "<iso8601>",
|
||||
"sources": ["<source-name>", ...],
|
||||
"urls": ["<permalink>", ...]
|
||||
}
|
||||
},
|
||||
"aliases": { "<alt_id>": "<canonical_id>" }
|
||||
}
|
||||
"""
|
||||
from __future__ import annotations
|
||||
|
||||
import datetime
|
||||
import json
|
||||
import pathlib
|
||||
from typing import Any
|
||||
|
||||
|
||||
STATE_PATH = pathlib.Path("state/seen.json")
|
||||
SCHEMA_VERSION = 2
|
||||
|
||||
|
||||
def empty() -> dict[str, Any]:
|
||||
return {
|
||||
"schema_version": SCHEMA_VERSION,
|
||||
"last_run": None,
|
||||
"sources": {},
|
||||
"seen": {},
|
||||
"aliases": {},
|
||||
}
|
||||
|
||||
|
||||
def load(path: pathlib.Path = STATE_PATH) -> dict[str, Any]:
|
||||
if not path.exists():
|
||||
# Fallback: a committed bootstrap seed, used to bridge a workflow
|
||||
# rename (old workflow_id's artifacts are invisible to the new one).
|
||||
# Remove the bootstrap file once one successful run has produced a
|
||||
# normal artifact, otherwise it will shadow any future first-run.
|
||||
bootstrap = path.parent / f"{path.name}.bootstrap"
|
||||
if bootstrap.exists():
|
||||
print(f"state: seeding from {bootstrap} (no prior-run artifact found)")
|
||||
path = bootstrap
|
||||
if not path.exists():
|
||||
return empty()
|
||||
data = json.loads(path.read_text())
|
||||
return _migrate(data)
|
||||
|
||||
|
||||
def save(data: dict[str, Any], path: pathlib.Path = STATE_PATH) -> None:
|
||||
path.parent.mkdir(parents=True, exist_ok=True)
|
||||
path.write_text(json.dumps(data, indent=2, sort_keys=True) + "\n")
|
||||
|
||||
|
||||
def _migrate(data: dict[str, Any]) -> dict[str, Any]:
|
||||
"""Bring any older schema up to SCHEMA_VERSION."""
|
||||
version = data.get("schema_version")
|
||||
if version == SCHEMA_VERSION:
|
||||
data.setdefault("sources", {})
|
||||
data.setdefault("aliases", {})
|
||||
data.setdefault("seen", {})
|
||||
return data
|
||||
|
||||
# v1 shape: {"last_run": ..., "seen": {<id>: {bucket, seen_at, source, cve?}}}
|
||||
migrated_seen: dict[str, Any] = {}
|
||||
aliases: dict[str, str] = {}
|
||||
for key, entry in (data.get("seen") or {}).items():
|
||||
rec = {
|
||||
"bucket": entry.get("bucket", "unrelated"),
|
||||
"seen_at": entry.get("seen_at"),
|
||||
"sources": [entry["source"]] if entry.get("source") else [],
|
||||
"urls": [key] if isinstance(key, str) and key.startswith("http") else [],
|
||||
}
|
||||
migrated_seen[key] = rec
|
||||
# If a v1 entry had a CVE that differs from the key, alias the CVE -> key.
|
||||
cve = entry.get("cve")
|
||||
if cve and cve != key:
|
||||
aliases[cve] = key
|
||||
|
||||
return {
|
||||
"schema_version": SCHEMA_VERSION,
|
||||
"last_run": data.get("last_run"),
|
||||
"sources": {},
|
||||
"seen": migrated_seen,
|
||||
"aliases": aliases,
|
||||
}
|
||||
|
||||
|
||||
def lookup(data: dict[str, Any], candidate_ids: list[str]) -> str | None:
|
||||
"""Return the canonical key if any candidate is already known, else None."""
|
||||
seen = data["seen"]
|
||||
aliases = data["aliases"]
|
||||
for cid in candidate_ids:
|
||||
if not cid:
|
||||
continue
|
||||
if cid in seen:
|
||||
return cid
|
||||
canonical = aliases.get(cid)
|
||||
if canonical and canonical in seen:
|
||||
return canonical
|
||||
return None
|
||||
|
||||
|
||||
_BUCKET_STRENGTH = {"unrelated": 0, "tocheck": 1, "toimplement": 2}
|
||||
|
||||
|
||||
def promote_bucket(current: str, incoming: str) -> str:
|
||||
"""Return whichever of two buckets represents the 'stronger' classification."""
|
||||
return incoming if _BUCKET_STRENGTH.get(incoming, 0) > _BUCKET_STRENGTH.get(current, 0) else current
|
||||
|
||||
|
||||
def prune(data: dict[str, Any], days: int, now: datetime.datetime) -> tuple[int, int]:
|
||||
"""Drop seen entries older than `days`, and aliases pointing at dropped keys."""
|
||||
cutoff = (now - datetime.timedelta(days=days)).isoformat()
|
||||
before = len(data["seen"])
|
||||
data["seen"] = {
|
||||
k: v for k, v in data["seen"].items()
|
||||
if (v.get("seen_at") or "9999") >= cutoff
|
||||
}
|
||||
data["aliases"] = {k: v for k, v in data["aliases"].items() if v in data["seen"]}
|
||||
return before, len(data["seen"])
|
||||
File diff suppressed because it is too large
Load Diff
@@ -0,0 +1,824 @@
|
||||
{
|
||||
"aliases": {
|
||||
"CVE-2018-3615": "CVE-2018-3646",
|
||||
"CVE-2018-3620": "CVE-2018-3646",
|
||||
"CVE-2025-54505": "https://www.phoronix.com/news/AMD-FP-DSS-Zen-1-Bug",
|
||||
"CVE-2026-33691": "https://seclists.org/oss-sec/2026/q2/175",
|
||||
"CVE-2026-41113": "https://seclists.org/oss-sec/2026/q2/176",
|
||||
"CVE-2026-4519": "CVE-2026-4786",
|
||||
"https://msrc.microsoft.com/update-guide/vulnerability/CVE-2026-33055": "CVE-2026-33055",
|
||||
"https://msrc.microsoft.com/update-guide/vulnerability/CVE-2026-33056": "CVE-2026-33056",
|
||||
"https://msrc.microsoft.com/update-guide/vulnerability/CVE-2026-4786": "CVE-2026-4786",
|
||||
"https://msrc.microsoft.com/update-guide/vulnerability/CVE-2026-5160": "CVE-2026-5160",
|
||||
"https://msrc.microsoft.com/update-guide/vulnerability/CVE-2026-6100": "CVE-2026-6100",
|
||||
"https://seclists.org/oss-sec/2026/q2/173": "CVE-2026-33691",
|
||||
"https://seclists.org/oss-sec/2026/q2/176": "CVE-2026-41113",
|
||||
"https://transient.fail/": "CVE-2019-11091"
|
||||
},
|
||||
"last_run": "2026-04-19T14:06:07.928573+00:00",
|
||||
"schema_version": 2,
|
||||
"seen": {
|
||||
"AMD-SB-7050": {
|
||||
"bucket": "tocheck",
|
||||
"first_seen": "2026-04-18T14:24:43Z",
|
||||
"seen_at": "2026-04-18T14:24:43Z",
|
||||
"sources": [
|
||||
"amd-psirt"
|
||||
],
|
||||
"title": "",
|
||||
"urls": []
|
||||
},
|
||||
"AMD-SB-7053": {
|
||||
"bucket": "toimplement",
|
||||
"first_seen": "2026-04-18T14:24:43Z",
|
||||
"seen_at": "2026-04-18T14:24:43Z",
|
||||
"sources": [
|
||||
"amd-psirt"
|
||||
],
|
||||
"title": "",
|
||||
"urls": []
|
||||
},
|
||||
"CVE-2017-5715": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-19T14:06:07.928573+00:00",
|
||||
"seen_at": "2026-04-19T14:06:07.928573+00:00",
|
||||
"sources": [
|
||||
"transient-fail"
|
||||
],
|
||||
"title": "CVE-2017-5715",
|
||||
"urls": [
|
||||
"https://transient.fail/"
|
||||
]
|
||||
},
|
||||
"CVE-2017-5753": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-19T14:06:07.928573+00:00",
|
||||
"seen_at": "2026-04-19T14:06:07.928573+00:00",
|
||||
"sources": [
|
||||
"transient-fail"
|
||||
],
|
||||
"title": "CVE-2017-5753",
|
||||
"urls": [
|
||||
"https://transient.fail/"
|
||||
]
|
||||
},
|
||||
"CVE-2017-5754": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-19T14:06:07.928573+00:00",
|
||||
"seen_at": "2026-04-19T14:06:07.928573+00:00",
|
||||
"sources": [
|
||||
"transient-fail"
|
||||
],
|
||||
"title": "CVE-2017-5754",
|
||||
"urls": [
|
||||
"https://transient.fail/"
|
||||
]
|
||||
},
|
||||
"CVE-2018-12126": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-19T14:06:07.928573+00:00",
|
||||
"seen_at": "2026-04-19T14:06:07.928573+00:00",
|
||||
"sources": [
|
||||
"transient-fail"
|
||||
],
|
||||
"title": "CVE-2018-12126",
|
||||
"urls": [
|
||||
"https://transient.fail/"
|
||||
]
|
||||
},
|
||||
"CVE-2018-12127": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-19T14:06:07.928573+00:00",
|
||||
"seen_at": "2026-04-19T14:06:07.928573+00:00",
|
||||
"sources": [
|
||||
"transient-fail"
|
||||
],
|
||||
"title": "CVE-2018-12127",
|
||||
"urls": [
|
||||
"https://transient.fail/"
|
||||
]
|
||||
},
|
||||
"CVE-2018-12130": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-19T14:06:07.928573+00:00",
|
||||
"seen_at": "2026-04-19T14:06:07.928573+00:00",
|
||||
"sources": [
|
||||
"transient-fail"
|
||||
],
|
||||
"title": "CVE-2018-12130",
|
||||
"urls": [
|
||||
"https://transient.fail/"
|
||||
]
|
||||
},
|
||||
"CVE-2018-3639": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-19T14:06:07.928573+00:00",
|
||||
"seen_at": "2026-04-19T14:06:07.928573+00:00",
|
||||
"sources": [
|
||||
"transient-fail"
|
||||
],
|
||||
"title": "CVE-2018-3639",
|
||||
"urls": [
|
||||
"https://transient.fail/"
|
||||
]
|
||||
},
|
||||
"CVE-2018-3640": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-19T14:06:07.928573+00:00",
|
||||
"seen_at": "2026-04-19T14:06:07.928573+00:00",
|
||||
"sources": [
|
||||
"transient-fail"
|
||||
],
|
||||
"title": "CVE-2018-3640",
|
||||
"urls": [
|
||||
"https://transient.fail/"
|
||||
]
|
||||
},
|
||||
"CVE-2018-3646": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-19T14:06:07.928573+00:00",
|
||||
"seen_at": "2026-04-19T14:06:07.928573+00:00",
|
||||
"sources": [
|
||||
"transient-fail"
|
||||
],
|
||||
"title": "CVE-2018-3615",
|
||||
"urls": [
|
||||
"https://transient.fail/"
|
||||
]
|
||||
},
|
||||
"CVE-2018-3665": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-19T14:06:07.928573+00:00",
|
||||
"seen_at": "2026-04-19T14:06:07.928573+00:00",
|
||||
"sources": [
|
||||
"transient-fail"
|
||||
],
|
||||
"title": "CVE-2018-3665",
|
||||
"urls": [
|
||||
"https://transient.fail/"
|
||||
]
|
||||
},
|
||||
"CVE-2019-11091": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-19T14:06:07.928573+00:00",
|
||||
"seen_at": "2026-04-19T14:06:07.928573+00:00",
|
||||
"sources": [
|
||||
"transient-fail"
|
||||
],
|
||||
"title": "CVE-2019-11091",
|
||||
"urls": [
|
||||
"https://transient.fail/"
|
||||
]
|
||||
},
|
||||
"CVE-2019-11135": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-19T14:06:07.928573+00:00",
|
||||
"seen_at": "2026-04-19T14:06:07.928573+00:00",
|
||||
"sources": [
|
||||
"transient-fail"
|
||||
],
|
||||
"title": "CVE-2019-11135",
|
||||
"urls": [
|
||||
"https://transient.fail/"
|
||||
]
|
||||
},
|
||||
"CVE-2025-66335": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-18T14:24:43Z",
|
||||
"seen_at": "2026-04-18T14:24:43Z",
|
||||
"sources": [
|
||||
"oss-sec"
|
||||
],
|
||||
"title": "",
|
||||
"urls": []
|
||||
},
|
||||
"CVE-2026-25917": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-18T14:24:43Z",
|
||||
"seen_at": "2026-04-18T14:24:43Z",
|
||||
"sources": [
|
||||
"oss-sec"
|
||||
],
|
||||
"title": "",
|
||||
"urls": []
|
||||
},
|
||||
"CVE-2026-30898": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-18T14:24:43Z",
|
||||
"seen_at": "2026-04-18T14:24:43Z",
|
||||
"sources": [
|
||||
"oss-sec"
|
||||
],
|
||||
"title": "",
|
||||
"urls": []
|
||||
},
|
||||
"CVE-2026-30912": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-18T14:24:43Z",
|
||||
"seen_at": "2026-04-18T14:24:43Z",
|
||||
"sources": [
|
||||
"oss-sec"
|
||||
],
|
||||
"title": "",
|
||||
"urls": []
|
||||
},
|
||||
"CVE-2026-32228": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-18T14:24:43Z",
|
||||
"seen_at": "2026-04-18T14:24:43Z",
|
||||
"sources": [
|
||||
"oss-sec"
|
||||
],
|
||||
"title": "",
|
||||
"urls": []
|
||||
},
|
||||
"CVE-2026-32690": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-18T14:24:43Z",
|
||||
"seen_at": "2026-04-18T14:24:43Z",
|
||||
"sources": [
|
||||
"oss-sec"
|
||||
],
|
||||
"title": "",
|
||||
"urls": []
|
||||
},
|
||||
"CVE-2026-33055": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-19T14:06:07.928573+00:00",
|
||||
"seen_at": "2026-04-19T14:06:07.928573+00:00",
|
||||
"sources": [
|
||||
"msrc"
|
||||
],
|
||||
"title": "CVE-2026-33055 tar-rs incorrectly ignores PAX size headers if header size is nonzero",
|
||||
"urls": [
|
||||
"https://msrc.microsoft.com/update-guide/vulnerability/CVE-2026-33055"
|
||||
]
|
||||
},
|
||||
"CVE-2026-33056": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-19T14:06:07.928573+00:00",
|
||||
"seen_at": "2026-04-19T14:06:07.928573+00:00",
|
||||
"sources": [
|
||||
"msrc"
|
||||
],
|
||||
"title": "CVE-2026-33056 tar-rs: unpack_in can chmod arbitrary directories by following symlinks",
|
||||
"urls": [
|
||||
"https://msrc.microsoft.com/update-guide/vulnerability/CVE-2026-33056"
|
||||
]
|
||||
},
|
||||
"CVE-2026-33691": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-19T14:06:07.928573+00:00",
|
||||
"seen_at": "2026-04-19T14:06:07.928573+00:00",
|
||||
"sources": [
|
||||
"oss-sec"
|
||||
],
|
||||
"title": "Re: [CVE-2026-33691] OWASP CRS whitespace padding bypass vulnerability",
|
||||
"urls": [
|
||||
"https://seclists.org/oss-sec/2026/q2/173",
|
||||
"https://seclists.org/oss-sec/2026/q2/174",
|
||||
"https://seclists.org/oss-sec/2026/q2/175"
|
||||
]
|
||||
},
|
||||
"CVE-2026-39314": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-18T14:24:43Z",
|
||||
"seen_at": "2026-04-18T14:24:43Z",
|
||||
"sources": [
|
||||
"oss-sec"
|
||||
],
|
||||
"title": "",
|
||||
"urls": []
|
||||
},
|
||||
"CVE-2026-40170": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-18T14:24:43Z",
|
||||
"seen_at": "2026-04-18T14:24:43Z",
|
||||
"sources": [
|
||||
"oss-sec"
|
||||
],
|
||||
"title": "",
|
||||
"urls": []
|
||||
},
|
||||
"CVE-2026-40948": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-18T14:24:43Z",
|
||||
"seen_at": "2026-04-18T14:24:43Z",
|
||||
"sources": [
|
||||
"oss-sec"
|
||||
],
|
||||
"title": "",
|
||||
"urls": []
|
||||
},
|
||||
"CVE-2026-41113": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-19T14:06:07.928573+00:00",
|
||||
"seen_at": "2026-04-19T14:06:07.928573+00:00",
|
||||
"sources": [
|
||||
"oss-sec"
|
||||
],
|
||||
"title": "CVE-2026-41113: RCE in sagredo fork of qmail",
|
||||
"urls": [
|
||||
"https://seclists.org/oss-sec/2026/q2/176"
|
||||
]
|
||||
},
|
||||
"CVE-2026-41254": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-18T14:24:43Z",
|
||||
"seen_at": "2026-04-18T14:24:43Z",
|
||||
"sources": [
|
||||
"oss-sec"
|
||||
],
|
||||
"title": "",
|
||||
"urls": []
|
||||
},
|
||||
"CVE-2026-4786": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-19T14:06:07.928573+00:00",
|
||||
"seen_at": "2026-04-19T14:06:07.928573+00:00",
|
||||
"sources": [
|
||||
"msrc"
|
||||
],
|
||||
"title": "CVE-2026-4786 Incomplete mitigation of CVE-2026-4519, %action expansion for command injection to webbrowser.open()",
|
||||
"urls": [
|
||||
"https://msrc.microsoft.com/update-guide/vulnerability/CVE-2026-4786"
|
||||
]
|
||||
},
|
||||
"CVE-2026-5160": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-19T14:06:07.928573+00:00",
|
||||
"seen_at": "2026-04-19T14:06:07.928573+00:00",
|
||||
"sources": [
|
||||
"msrc"
|
||||
],
|
||||
"title": "CVE-2026-5160",
|
||||
"urls": [
|
||||
"https://msrc.microsoft.com/update-guide/vulnerability/CVE-2026-5160"
|
||||
]
|
||||
},
|
||||
"CVE-2026-6100": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-19T14:06:07.928573+00:00",
|
||||
"seen_at": "2026-04-19T14:06:07.928573+00:00",
|
||||
"sources": [
|
||||
"msrc"
|
||||
],
|
||||
"title": "CVE-2026-6100 Use-after-free in lzma.LZMADecompressor, bz2.BZ2Decompressor, and gzip.GzipFile after re-use under memory pressure",
|
||||
"urls": [
|
||||
"https://msrc.microsoft.com/update-guide/vulnerability/CVE-2026-6100"
|
||||
]
|
||||
},
|
||||
"https://lwn.net/Articles/1066156/": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-18T14:24:43Z",
|
||||
"seen_at": "2026-04-18T14:24:43Z",
|
||||
"sources": [
|
||||
"lwn"
|
||||
],
|
||||
"title": "",
|
||||
"urls": [
|
||||
"https://lwn.net/Articles/1066156/"
|
||||
]
|
||||
},
|
||||
"https://lwn.net/Articles/1067029/": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-18T14:24:43Z",
|
||||
"seen_at": "2026-04-18T14:24:43Z",
|
||||
"sources": [
|
||||
"lwn"
|
||||
],
|
||||
"title": "",
|
||||
"urls": [
|
||||
"https://lwn.net/Articles/1067029/"
|
||||
]
|
||||
},
|
||||
"https://lwn.net/Articles/1068400/": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-18T14:24:43Z",
|
||||
"seen_at": "2026-04-18T14:24:43Z",
|
||||
"sources": [
|
||||
"lwn"
|
||||
],
|
||||
"title": "",
|
||||
"urls": [
|
||||
"https://lwn.net/Articles/1068400/"
|
||||
]
|
||||
},
|
||||
"https://lwn.net/Articles/1068473/": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-19T14:06:07.928573+00:00",
|
||||
"seen_at": "2026-04-19T14:06:07.928573+00:00",
|
||||
"sources": [
|
||||
"lwn"
|
||||
],
|
||||
"title": "Seven stable kernels for Saturday",
|
||||
"urls": [
|
||||
"https://lwn.net/Articles/1068473/"
|
||||
]
|
||||
},
|
||||
"https://seclists.org/oss-sec/2026/q2/164": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-18T14:24:43Z",
|
||||
"seen_at": "2026-04-18T14:24:43Z",
|
||||
"sources": [
|
||||
"oss-sec"
|
||||
],
|
||||
"title": "",
|
||||
"urls": [
|
||||
"https://seclists.org/oss-sec/2026/q2/164"
|
||||
]
|
||||
},
|
||||
"https://seclists.org/oss-sec/2026/q2/167": {
|
||||
"bucket": "toimplement",
|
||||
"first_seen": "2026-04-18T14:24:43Z",
|
||||
"seen_at": "2026-04-18T14:24:43Z",
|
||||
"sources": [
|
||||
"oss-sec"
|
||||
],
|
||||
"title": "",
|
||||
"urls": [
|
||||
"https://seclists.org/oss-sec/2026/q2/167"
|
||||
]
|
||||
},
|
||||
"https://seclists.org/oss-sec/2026/q2/169": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-18T14:24:43Z",
|
||||
"seen_at": "2026-04-18T14:24:43Z",
|
||||
"sources": [
|
||||
"oss-sec"
|
||||
],
|
||||
"title": "",
|
||||
"urls": [
|
||||
"https://seclists.org/oss-sec/2026/q2/169"
|
||||
]
|
||||
},
|
||||
"https://seclists.org/oss-sec/2026/q2/170": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-18T14:24:43Z",
|
||||
"seen_at": "2026-04-18T14:24:43Z",
|
||||
"sources": [
|
||||
"oss-sec"
|
||||
],
|
||||
"title": "",
|
||||
"urls": [
|
||||
"https://seclists.org/oss-sec/2026/q2/170"
|
||||
]
|
||||
},
|
||||
"https://seclists.org/oss-sec/2026/q2/171": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-18T14:24:43Z",
|
||||
"seen_at": "2026-04-18T14:24:43Z",
|
||||
"sources": [
|
||||
"oss-sec"
|
||||
],
|
||||
"title": "",
|
||||
"urls": [
|
||||
"https://seclists.org/oss-sec/2026/q2/171"
|
||||
]
|
||||
},
|
||||
"https://seclists.org/oss-sec/2026/q2/172": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-19T09:01:57Z",
|
||||
"seen_at": "2026-04-19T09:01:57Z",
|
||||
"sources": [
|
||||
"oss-sec"
|
||||
],
|
||||
"title": "",
|
||||
"urls": [
|
||||
"https://seclists.org/oss-sec/2026/q2/172"
|
||||
]
|
||||
},
|
||||
"https://seclists.org/oss-sec/2026/q2/173": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-19T09:01:57Z",
|
||||
"seen_at": "2026-04-19T09:01:57Z",
|
||||
"sources": [
|
||||
"oss-sec"
|
||||
],
|
||||
"title": "",
|
||||
"urls": [
|
||||
"https://seclists.org/oss-sec/2026/q2/173"
|
||||
]
|
||||
},
|
||||
"https://seclists.org/oss-sec/2026/q2/174": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-19T09:01:57Z",
|
||||
"seen_at": "2026-04-19T09:01:57Z",
|
||||
"sources": [
|
||||
"oss-sec"
|
||||
],
|
||||
"title": "",
|
||||
"urls": [
|
||||
"https://seclists.org/oss-sec/2026/q2/174"
|
||||
]
|
||||
},
|
||||
"https://seclists.org/oss-sec/2026/q2/175": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-19T09:01:57Z",
|
||||
"seen_at": "2026-04-19T09:01:57Z",
|
||||
"sources": [
|
||||
"oss-sec"
|
||||
],
|
||||
"title": "",
|
||||
"urls": [
|
||||
"https://seclists.org/oss-sec/2026/q2/175"
|
||||
]
|
||||
},
|
||||
"https://seclists.org/oss-sec/2026/q2/176": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-19T09:01:57Z",
|
||||
"seen_at": "2026-04-19T09:01:57Z",
|
||||
"sources": [
|
||||
"oss-sec"
|
||||
],
|
||||
"title": "",
|
||||
"urls": [
|
||||
"https://seclists.org/oss-sec/2026/q2/176"
|
||||
]
|
||||
},
|
||||
"https://www.phoronix.com/news/AMD-2026-New-SMCA-Bank-Types": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-19T14:06:07.928573+00:00",
|
||||
"seen_at": "2026-04-19T14:06:07.928573+00:00",
|
||||
"sources": [
|
||||
"phoronix"
|
||||
],
|
||||
"title": "Linux 7.1 Adds New AMD SMCA Bank Types, Presumably For Upcoming EPYC Venice",
|
||||
"urls": [
|
||||
"https://www.phoronix.com/news/AMD-2026-New-SMCA-Bank-Types"
|
||||
]
|
||||
},
|
||||
"https://www.phoronix.com/news/AMD-FP-DSS-Zen-1-Bug": {
|
||||
"bucket": "toimplement",
|
||||
"first_seen": "2026-04-18T14:24:43Z",
|
||||
"seen_at": "2026-04-18T14:24:43Z",
|
||||
"sources": [
|
||||
"phoronix"
|
||||
],
|
||||
"title": "",
|
||||
"urls": [
|
||||
"https://www.phoronix.com/news/AMD-FP-DSS-Zen-1-Bug"
|
||||
]
|
||||
},
|
||||
"https://www.phoronix.com/news/AMD-Harvested-GPUs-Linux": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-19T14:06:07.928573+00:00",
|
||||
"seen_at": "2026-04-19T14:06:07.928573+00:00",
|
||||
"sources": [
|
||||
"phoronix"
|
||||
],
|
||||
"title": "Valve Developer Further Improves Old AMD GPUs: HD 7870 XT Finally Working On Linux",
|
||||
"urls": [
|
||||
"https://www.phoronix.com/news/AMD-Harvested-GPUs-Linux"
|
||||
]
|
||||
},
|
||||
"https://www.phoronix.com/news/AMD-RDNA4m-RADV-ACO": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-18T14:24:43Z",
|
||||
"seen_at": "2026-04-18T14:24:43Z",
|
||||
"sources": [
|
||||
"phoronix"
|
||||
],
|
||||
"title": "",
|
||||
"urls": [
|
||||
"https://www.phoronix.com/news/AMD-RDNA4m-RADV-ACO"
|
||||
]
|
||||
},
|
||||
"https://www.phoronix.com/news/CachyOS-Super-Charged-Linux-7.0": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-19T14:06:07.928573+00:00",
|
||||
"seen_at": "2026-04-19T14:06:07.928573+00:00",
|
||||
"sources": [
|
||||
"phoronix"
|
||||
],
|
||||
"title": "CachyOS Rolls Out A Super-Charged Linux 7.0 Kernel",
|
||||
"urls": [
|
||||
"https://www.phoronix.com/news/CachyOS-Super-Charged-Linux-7.0"
|
||||
]
|
||||
},
|
||||
"https://www.phoronix.com/news/GNOME-Graphs-2.0-Maps-Transit": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-18T14:24:43Z",
|
||||
"seen_at": "2026-04-18T14:24:43Z",
|
||||
"sources": [
|
||||
"phoronix"
|
||||
],
|
||||
"title": "",
|
||||
"urls": [
|
||||
"https://www.phoronix.com/news/GNOME-Graphs-2.0-Maps-Transit"
|
||||
]
|
||||
},
|
||||
"https://www.phoronix.com/news/GhostBSD-26.1-R15.0p2": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-19T14:06:07.928573+00:00",
|
||||
"seen_at": "2026-04-19T14:06:07.928573+00:00",
|
||||
"sources": [
|
||||
"phoronix"
|
||||
],
|
||||
"title": "GhostBSD 26.1 Now Based On FreeBSD 15.0, Switches to XLibre X Server",
|
||||
"urls": [
|
||||
"https://www.phoronix.com/news/GhostBSD-26.1-R15.0p2"
|
||||
]
|
||||
},
|
||||
"https://www.phoronix.com/news/KDE-Plasma-6.7-Session": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-18T14:24:43Z",
|
||||
"seen_at": "2026-04-18T14:24:43Z",
|
||||
"sources": [
|
||||
"phoronix"
|
||||
],
|
||||
"title": "",
|
||||
"urls": [
|
||||
"https://www.phoronix.com/news/KDE-Plasma-6.7-Session"
|
||||
]
|
||||
},
|
||||
"https://www.phoronix.com/news/Linux-7.1-Block-Changes": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-19T14:06:07.928573+00:00",
|
||||
"seen_at": "2026-04-19T14:06:07.928573+00:00",
|
||||
"sources": [
|
||||
"phoronix"
|
||||
],
|
||||
"title": "Linux 7.1 Sees RAID Fixes, IO_uring Enhancements",
|
||||
"urls": [
|
||||
"https://www.phoronix.com/news/Linux-7.1-Block-Changes"
|
||||
]
|
||||
},
|
||||
"https://www.phoronix.com/news/Linux-7.1-Crypto-QAT-Zstd": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-19T14:06:07.928573+00:00",
|
||||
"seen_at": "2026-04-19T14:06:07.928573+00:00",
|
||||
"sources": [
|
||||
"phoronix"
|
||||
],
|
||||
"title": "Intel QAT Zstd, QAT Gen6 Improvements Merged For Linux 7.1",
|
||||
"urls": [
|
||||
"https://www.phoronix.com/news/Linux-7.1-Crypto-QAT-Zstd"
|
||||
]
|
||||
},
|
||||
"https://www.phoronix.com/news/Linux-7.1-HRTIMER-Overhaul": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-18T14:24:43Z",
|
||||
"seen_at": "2026-04-18T14:24:43Z",
|
||||
"sources": [
|
||||
"phoronix"
|
||||
],
|
||||
"title": "",
|
||||
"urls": [
|
||||
"https://www.phoronix.com/news/Linux-7.1-HRTIMER-Overhaul"
|
||||
]
|
||||
},
|
||||
"https://www.phoronix.com/news/Linux-7.1-New-NTFS-Driver": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-18T14:24:43Z",
|
||||
"seen_at": "2026-04-18T14:24:43Z",
|
||||
"sources": [
|
||||
"phoronix"
|
||||
],
|
||||
"title": "",
|
||||
"urls": [
|
||||
"https://www.phoronix.com/news/Linux-7.1-New-NTFS-Driver"
|
||||
]
|
||||
},
|
||||
"https://www.phoronix.com/news/Linux-7.1-Scheduler": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-18T14:24:43Z",
|
||||
"seen_at": "2026-04-18T14:24:43Z",
|
||||
"sources": [
|
||||
"phoronix"
|
||||
],
|
||||
"title": "",
|
||||
"urls": [
|
||||
"https://www.phoronix.com/news/Linux-7.1-Scheduler"
|
||||
]
|
||||
},
|
||||
"https://www.phoronix.com/news/Linux-7.1-Sound": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-19T14:06:07.928573+00:00",
|
||||
"seen_at": "2026-04-19T14:06:07.928573+00:00",
|
||||
"sources": [
|
||||
"phoronix"
|
||||
],
|
||||
"title": "Linux 7.1 Sound Code Adds Bus Keepers: Aiming For Better Apple Silicon Support",
|
||||
"urls": [
|
||||
"https://www.phoronix.com/news/Linux-7.1-Sound"
|
||||
]
|
||||
},
|
||||
"https://www.phoronix.com/news/Wine-11.7-Released": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-18T14:24:43Z",
|
||||
"seen_at": "2026-04-18T14:24:43Z",
|
||||
"sources": [
|
||||
"phoronix"
|
||||
],
|
||||
"title": "",
|
||||
"urls": [
|
||||
"https://www.phoronix.com/news/Wine-11.7-Released"
|
||||
]
|
||||
},
|
||||
"https://www.phoronix.com/news/WireGuard-For-Windows-1.0": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-19T14:06:07.928573+00:00",
|
||||
"seen_at": "2026-04-19T14:06:07.928573+00:00",
|
||||
"sources": [
|
||||
"phoronix"
|
||||
],
|
||||
"title": "WireGuard For Windows Reaches v1.0",
|
||||
"urls": [
|
||||
"https://www.phoronix.com/news/WireGuard-For-Windows-1.0"
|
||||
]
|
||||
},
|
||||
"https://www.phoronix.com/review/ubuntu-2604-xe2-lunar-lake": {
|
||||
"bucket": "unrelated",
|
||||
"first_seen": "2026-04-18T14:24:43Z",
|
||||
"seen_at": "2026-04-18T14:24:43Z",
|
||||
"sources": [
|
||||
"phoronix"
|
||||
],
|
||||
"title": "",
|
||||
"urls": [
|
||||
"https://www.phoronix.com/review/ubuntu-2604-xe2-lunar-lake"
|
||||
]
|
||||
}
|
||||
},
|
||||
"sources": {
|
||||
"amd-psirt": {
|
||||
"last_fetched_at": "2026-04-19T14:02:00.309888+00:00",
|
||||
"last_modified": "Sun, 19 Apr 2026 11:14:54 GMT",
|
||||
"last_status": 200
|
||||
},
|
||||
"arm-spec": {
|
||||
"etag": "\"c31f3bde81531617e355836b0f44bb05:1775559058.494352\"",
|
||||
"last_fetched_at": "2026-04-19T14:02:00.309888+00:00",
|
||||
"last_modified": "Tue, 07 Apr 2026 10:50:58 GMT",
|
||||
"last_status": 200
|
||||
},
|
||||
"cert-cc": {
|
||||
"last_fetched_at": "2026-04-19T14:02:00.309888+00:00",
|
||||
"last_modified": "Fri, 17 Apr 2026 16:57:16 GMT",
|
||||
"last_status": 200
|
||||
},
|
||||
"cisa": {
|
||||
"last_fetched_at": "2026-04-19T14:02:00.309888+00:00",
|
||||
"last_status": 200
|
||||
},
|
||||
"comsec-eth": {
|
||||
"etag": "W/\"ad4d6e03055d4fc084e06c1140e33311\"",
|
||||
"last_fetched_at": "2026-04-19T14:02:00.309888+00:00",
|
||||
"last_modified": "Fri, 17 Apr 2026 18:23:42 GMT",
|
||||
"last_status": 200
|
||||
},
|
||||
"intel-psirt": {
|
||||
"last_fetched_at": "2026-04-19T14:02:00.309888+00:00",
|
||||
"last_status": 200
|
||||
},
|
||||
"lwn": {
|
||||
"etag": "\"7a7f043e5c25da73032a33e230cd5adc23dce68d29b294dfdcaf96dcaf23a08c\"",
|
||||
"hwm_id": "https://lwn.net/Articles/1068473/",
|
||||
"hwm_published_at": "2026-04-18T15:48:08+00:00",
|
||||
"last_fetched_at": "2026-04-19T14:02:00.309888+00:00",
|
||||
"last_status": 200
|
||||
},
|
||||
"msrc": {
|
||||
"etag": "\"0x8DE9DE3F08E081D\"",
|
||||
"hwm_id": "CVE-2026-4786",
|
||||
"hwm_published_at": "2026-04-19T08:01:53+00:00",
|
||||
"last_fetched_at": "2026-04-19T14:02:00.309888+00:00",
|
||||
"last_modified": "Sun, 19 Apr 2026 07:19:05 GMT",
|
||||
"last_status": 200
|
||||
},
|
||||
"oss-sec": {
|
||||
"etag": "\"3ac0-64fc0e1ee44d0\"",
|
||||
"hwm_id": "CVE-2026-41113",
|
||||
"hwm_published_at": "2026-04-18T19:12:07+00:00",
|
||||
"last_fetched_at": "2026-04-19T14:02:00.309888+00:00",
|
||||
"last_modified": "Sat, 18 Apr 2026 19:15:03 GMT",
|
||||
"last_status": 200
|
||||
},
|
||||
"phoronix": {
|
||||
"hwm_id": "https://www.phoronix.com/news/AMD-Harvested-GPUs-Linux",
|
||||
"hwm_published_at": "2026-04-19T13:25:50+00:00",
|
||||
"last_fetched_at": "2026-04-19T14:02:00.309888+00:00",
|
||||
"last_status": 200
|
||||
},
|
||||
"project-zero": {
|
||||
"last_fetched_at": "2026-04-19T14:02:00.309888+00:00",
|
||||
"last_modified": "Tue, 31 Mar 2026 22:50:42 GMT",
|
||||
"last_status": 200
|
||||
},
|
||||
"transient-fail": {
|
||||
"etag": "W/\"67ab337f-158c5\"",
|
||||
"hwm_id": null,
|
||||
"hwm_published_at": null,
|
||||
"last_fetched_at": "2026-04-19T14:02:00.309888+00:00",
|
||||
"last_modified": "Tue, 11 Feb 2025 11:24:47 GMT",
|
||||
"last_status": 200
|
||||
},
|
||||
"vusec": {
|
||||
"etag": "W/\"6391ad5e2c03310cced577acfca52f46\"",
|
||||
"last_fetched_at": "2026-04-19T14:02:00.309888+00:00",
|
||||
"last_modified": "Mon, 16 Mar 2026 09:18:55 GMT",
|
||||
"last_status": 200
|
||||
}
|
||||
}
|
||||
}
|
||||
Reference in New Issue
Block a user